
MySQL 主从复制 完全上手指南
0x01 在说mysql主从复制之前,我们先来大致了解一些关于不同级别的同步方案
基于文件级别的同步
非实时同步1
scp/sftp/ftp/samba/rsync/union....
实时同步1
NFS/inotify/sersync/lsyncd....
基于文件系统级别的同步1
drbd...
基于数据库级别的同步,对于数据库而言基本都属于实时同步,但实时并不一定意味着就是同步操作,也可能是用异步的方式在操作1
2
3
4mysql replication 虽然异步的,但实现的效果基本上是实时的
oracle
redis
mongodb
直接利用程序进行 双写 也可实现实时同步的效果
0x02 关于 mysql 主从复制的一些常用方式:1
2
3
4一主一从,通常情况下,一主3到5个从为宜,另外,我们常说的mysql读写分离,一般都是主写,从读
一主多从
一主一主多从 多层级联,有一定延迟,通常会配合keeplive做高可用
...
0x03 深入理解 mysql 主从复制的内部实现细节,其实,究其原理极其的简单,想必大家也都比较熟练了,这里只做些简要回顾:
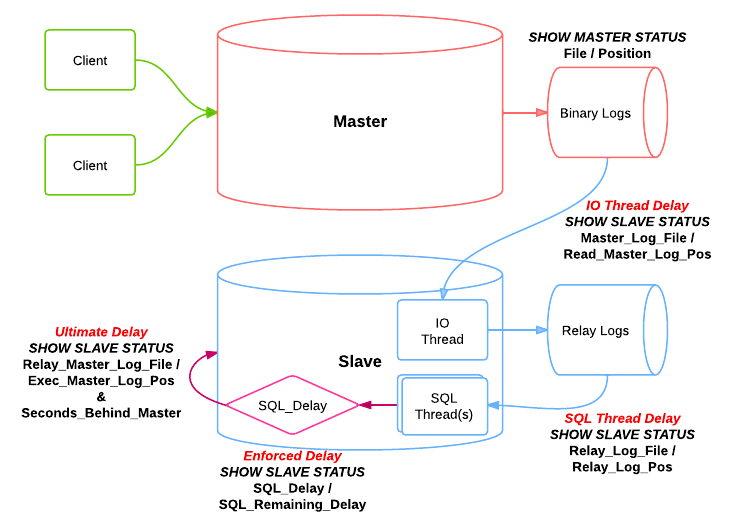
1
2
3
4
5
6首先,需要在主从库中同时开启mysql的bin log功能
此时,前端只要有任何 `增删改` `即 insert,update,delete,crate,drop,alter` 的操作时
除了到数据库中执行正常的该sql语句之外,它同时也会把该sql语句往bin log日志中写一份
注意,bin log文件是有大小限制的,默认最大会到1.1G,超过之后就会自动再新增一个文件
另外,还有有个单独的索引文件,是用来存放bin log文件名的,后续主要根据它来命中对应的bin log文件中的sql语句
最后,主库会起一个IO线程,主要用来等会儿和从库的IO线程进行数据传输
1 | 了解完主库,我们再来说从库,从库中此时会起两个线程,一个是IO线程,主要用来到主库中去取sql语句 |
1 | 最后,需要注意的是,如果主从复制直接是从 `0` 开始,也就是说,主从库中的数据事先就是完全一致的 |
0x04 演示环境,注意,做主从复制的数据库版本务必完全一致,否则复制时会有一些意外问题1
2
3MysqlMaster 最小化安装 已配置好的mysql 5.6.27 eth0: 192.168.3.45 eth1: 192.168.4.17 eth2: 192.168.5.17 Master
MysqlSlave 最小化安装 已配置好的mysql 5.6.27 eth0: 192.168.3.46 eth1: 192.168.4.18 eth2: 192.168.5.18 Slave
MysqlSlave1 最小化安装 已配置好的mysql 5.6.27 eth0: 192.168.3.52 eth1: 192.168.4.19 eth2: 192.168.5.19 Slave1
首先,在主从库上同时 开启bin log功能,这样做主要是为了方便后续做级联 ,去 mysql的配置文件my.cnf 中修改如下配置1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# vi /etc/my.cnf 在主库的[mysqld]模块下配置
log_bin = master_bin
server_id = 1
slave-skip-errors = 1032,1062,1007,1008 为了防止在同步时报错,我们可以提前忽略一些不是非常重要的mysql错误状态码
# vi /etc/my.cnf 在从库的[mysqld]模块下配置,此处的id务必保持唯一
log_bin = slave_bin
server_id = 2
slave-skip-errors = 1032,1062,1007,1008
log-slave-updates
expire_logs_days = 10
# /etc/init.d/mysqld restart
# mysql -uroot -p
mysql> show variables like 'log_bin'; 查看bin log功能有无开启
mysql> show variables like "server_id"; 查看server_id还是不是我们刚刚设置好的
其次,在主库中授权一个专门用于主从复制的数据库用户1
2
3mysql> grant replication slave on *.* to 'rep'@'192.168.3.%' identified by 'admin';
mysql> flush privileges;
mysql> show grants for rep@'192.168.3.%'; 查看指定用户权限
最后,把主库的数据先完整导出来,务必记得,在导之前先手工锁表 [其实,也可以不用锁,具做法往后看],锁表主要是为了防止在dump时外部再有新数据写入造成索引不对应,锁完表后,当前mysql终端先不要退出,否则锁表就失效了,此时可以再另开一个终端去执行mysqldump操作1
2
3
4
5
6
7mysql> flush table with read lock; 锁表
mysql> show master status; 记录当前索引位置,以后要从这个位置的这个点进行主从复制,也就是如果binlog文件丢失,数据也就丢失了
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| master_bin.000001| 120 | | | |
+------------------+----------+--------------+------------------+-------------------+
新起一个终端,打包好主库中的所有数据1
# mysqldump -uroot -padmin --events -A -B|gzip > /opt/master_bak_$(date +%F).sql.gz
这里打包完以后注意下文件大小,有时候文件太小很可能就是没打上,先回去看看什么原因,搞定了以后再继续打,一般很可能都是因为参数选项写错1
2# ll /opt/
# du -h /opt/master_bak_2017-12-05.sql.gz
确认打完没什么问题后,再回头检查下索引,看看变没,如果没变说明锁的没问题,如果位置变了,说明打包时又有新数据写入了,则此次打包无效,需要回去重打1
2mysql> show master status; 再次检查索引位置是否和之前有变化
mysql> unlock tables; 上面步骤没什么问题就可以解锁了
上面所说的不用手工锁表的语句,如下,-x 选项 其实就是个全局锁,这样干主要是为了方便后续自己写脚本来管理,-F 选项则会生成一个新的bin log文件1
2
3# mysqldump -uroot -padmin -A -B -F --master-data=2 -x --events > /opt/master_all.sql
# mysqldump -uroot -padmin -A -B -F --master-data=2 -x --events|gzip > /opt/master_all.sql.gz
# mysqlbinlog /usr/local/mysql/mysql-bin.000001
0x05 当我们拿到主库的备份文件和索引位置之后,就可以去从库中执行还原操作了,这里纯粹是为了方便所以就直接用scp把备份的文件推到从库机器上了1
2
3
4# scp -P 22 /opt/master_bak_2017-12-05.sql.gz root@192.168.3.46:/opt/
# cd /opt/ && ll
# gunzip master_bak_2017-12-05.sql.gz
# mysql -uroot -padmin < /opt/master_bak_2017-12-05.sql
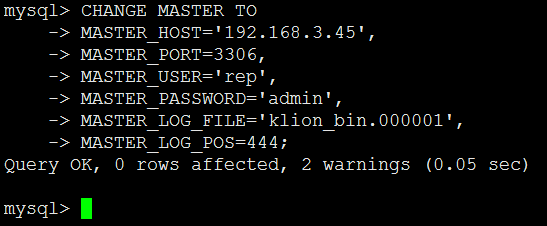
0x06 成功导入主库的备份文件后,需要在从库上配置和主库进行同步的一些必要参数,如下,注意,务必要严格按照下面的格式,防止出现各种空白符1
2
3
4
5
6
7
8# mysql -uroot -padmin
mysql> CHANGE MASTER TO
-> MASTER_HOST='192.168.3.45', 主库ip
-> MASTER_PORT=3306, 主库mysql端口
-> MASTER_USER='rep', 用于连接的数据库用户
-> MASTER_PASSWORD='admin', 用户密码
-> MASTER_LOG_FILE='master_bin.000001', 从我们上面备份的那个索引id开始
-> MASTER_LOG_POS=120; 索引位置是多少
1 | # cat /usr/local/mysql/data/master.info 查看刚刚写入的信息 |
在从库上开启IO和SQL线程1
2
3
4
5
6
7
8
9
10
11
12
13
14mysql> start slave; 启动slave功能
mysql> stop slave; 关闭slave功能
mysql> show slave status\G; 查看线程状态
Slave_IO_State: Connecting to master 看看有没有连上主库
Slave_IO_Running: Connecting IO 线程务必要起来
Slave_SQL_Running: Yes SQL 线程也务必要起来
Seconds_Behind_Master: NULL 从库落后主库的秒数,不太准,一般会自己在主从库中设置时间戳进行比较
Last_IO_Errno: 0 另外,平时如果出问题,要特别注意下IO和SQL线程的一些错误提示
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Last_Errno: 0
Last_Error:
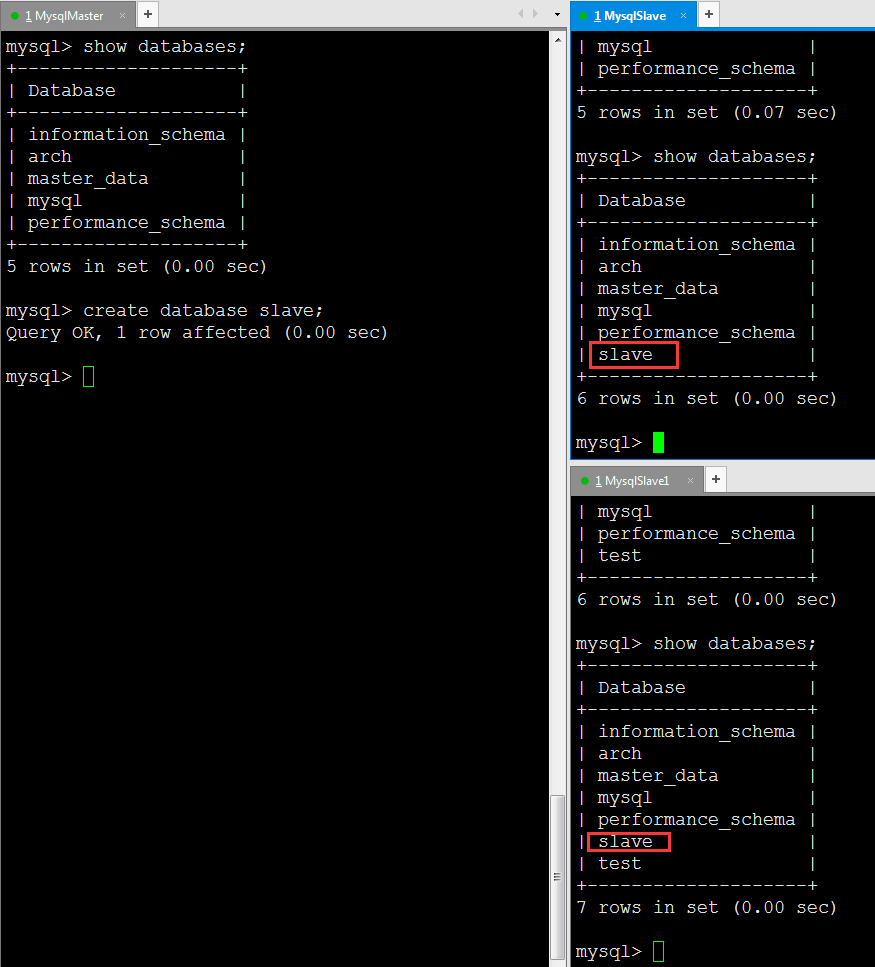
mysql> show databases; 最后回到主库中随便增删改,再到从库中看看有没有实时同步过来

0x07 上面是关于一主一从的实现过程,至于一主多从的实现就更简单了,先开启另一个从库的bin log功能,设置好server-id,注意id要保持唯一性,之后只需要把主库完整备份下顺手记录好索引id,然后还原到另一个需要同步的从库中,再加上之前从库的配置即可,注意,配置中的索引位置和文件要根据show master status;的结果做相应的调整:1
2
3
4
5
6
7# vi /etc/my.cnf
log_bin = slave1_bin
server_id = 3
# /etc/init.d/mysqld restart
# mysql -uroot -p
mysql> show variables like 'log_bin';
mysql> show variables like "server_id";

1 | mysql> CHANGE MASTER TO |
0x08 关于级联和双主[双写,索引id单双分开写]同步,只要时刻谨记,保持id唯一,要和谁同步,就在当前配置中去连接谁,这样,即使再多再复杂的级联也不会懵
小结:
整个配置过程,无任何技术含量,搞清楚内部运作细节才是最重要的





